
Collaborative Refining for Person Re-Identification With Label Noise
一种具有动态相互学习功能的在线协同精炼(CORE)框架,其中网络和标签预测通过从其他对等网络中提取知识来在线协作优化。
本文用于记录复现 CORE 的实验过程和结果,代码见 github仓库。
一、下载代码和数据集
1.1 代码
找一个目录,这里我使用的是我 fork 的仓库(私密的,你也可以自建一个,方便查看修改记录)
git clone https://gitee.com/zzyAJohn/ajohn-core.git使用下面命令可以输入一次账号密码后无需再次输入
git config --global credential.helper store1.2 数据集
克隆 Person_reID_baseline_pytorch,要用到里面的 prepare.py 来重命名数据集
git clone https://github.com/layumi/Person_reID_baseline_pytorch.git下载 Market1501 数据集,是一个 Market-1501-v15.09.15.zip 文件,145MB
pip install gdown
pip install --upgrade gdown #!!important!!
gdown 0B8-rUzbwVRk0c054eEozWG9COHMwsl访问不了谷歌可以wins下下载
使用unzip解压
apt install unzip
unzip Market-1501-v15.09.15.zip -d Market-1501-v15.09.15修改 prepare.py 中的 download_path2,不要修改 download_path,也不要创建download_path下的文件,下面函数会检查,download_path 是数据集的目标路径。如果该路径不存在,代码会尝试将另一个路径 download_path2 重命名为 download_path,以确保数据集存放在正确的位置。
download_path = '../Market' # Please not change.
download_path2 = '../Market-1501-v15.09.15' # You only need to change this line to your dataset download path
download_path2 = '../Market-1501-v15.09.15/Market-1501-v15.09.15' # You only need to change this line to your dataset download path 重命名数据集,会把所有图片移动到 Market\pytorch 下
python prepare.py把 pytorch 重命名为 market
每个文件按照类别编号
PS:我已经处理好的数据集,可以使用以下命令直接解压,等以后有空上传(
使用7zip解压
sudo apt update
sudo apt install p7zip-full
7z x re-id-market.7z二、环境配置
为了方便,我写了一个懒人脚本:
#!/bin/bash
# 创建 conda 环境
conda create --name core python=3.9 -y
# 激活 conda 环境并安装依赖
conda run -n core pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 检查 CUDA 是否可用
conda run -n core python -c "import torch; print(torch.cuda.is_available())"
echo "开始安装其他依赖:"
conda run -n core pip install tensorboardX scipy matplotlib easydict kornia ipykernel
echo "所有依赖项安装完成!"可以创建sh脚本执行:
touch core.sh
vim core.sh
# 复制进去保存
bash ./core.sh查看当前 cuda 版本
nvcc --version创建已有环境(可选)
conda env remove --name core创建环境
conda create --name core python=3.9 -y激活
conda activate core安装 Pytorch 参考Pytorch官网
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=11.8 -c pytorch -c nvidia或者安装慢可以用清华源
pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 --index-url https://pypi.tuna.tsinghua.edu.cn/simple检查 Pytorch 是否安装成功
python -c "import torch; print(torch.cuda.is_available())"输出:True
安装 core 所需依赖
pip install tensorboardXpip install scipypip install matplotlibpip install easydictpip install korniapip install ipykernelpip install scikit-learn管理员安装
sudo apt-get install libpython2.7如果遇到报错请参考 四、遇到的问题
三、运行程序
启动!1 个 epoch 需要 40 秒,150 个 epoch 接近 100 分钟。
注意后面路径是你 train 文件夹所在目录
python train_core_zzy.py --dataset re-id-market --batchsize 32 --noise_ratio 0.2 --lr 0.01 --data_dir ../dataset/四、遇到的问题
4.1 Cython 扩展模块的编译与导入不匹配
ImportError: dynamic module does not define module export function (PyInit_cython_eval)
(core) root@DESKTOP-5UQUCK2:/ajohn-lab-github/ReID-Label-Noise# python train_core.py --dataset market --batchsize 32 --noise_ratio 0.2 --lr 0.01 --pattern
Traceback (most recent call last):
File "/ajohn-lab-github/ReID-Label-Noise/train_core.py", line 28, in <module>
from eval_utils import get_test_acc, extract_train_second_label
File "/ajohn-lab-github/ReID-Label-Noise/eval_utils.py", line 8, in <module>
from eval_lib.cython_eval import eval_market1501_wrap
ImportError: dynamic module does not define module export function (PyInit_cython_eval)因为我们使用的是 python3.9,而 eval_lib 目录下只有 3.6 和 3.7 的编译的共享库。
进入 eval_lib 目录:
cd /ajohn-lab-github/ReID-Label-Noise/eval_lib使用 deadsnakes PPA,这个仓库提供了多个版本的 Python。
添加 deadsnakes PPA
sudo apt update
sudo apt install software-properties-common -y
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt-get update安装 Python 3.9 的开发包
sudo apt-get install python3.9 python3.9-dev安装 cython 和必要的编译工具
pip install cython
sudo apt-get update
sudo apt-get install build-essential python3.9-dev执行 setup.py 重新编译扩展模块
python3.9 setup.py build_ext --inplace在成功编译后,应该能看到生成了 eval.c 文件和 cython_eval.cpython-39-x86_64-linux-gnu.so 文件。
五、梳理
介绍
任务:
行人重识别(Re-ID)旨在匹配从不同摄像机获得的人员图像,这在计算机视觉研究和工业智能监控系统中发挥着重要作用。
存在的问题:
现有的行人重新识别(Re-ID)方法通常严重依赖大规模干净注释的训练数据。 然而,由于真实场景中的人物检测结果不准确或标注错误,标签噪声是不可避免的。 学习带有标签噪声的鲁棒 Re-ID 模型极具挑战性,因为每个身份的带注释训练样本非常有限。与图像分类任务相比,每个身份的训练样本非常有限,通常是数十到数千[11]。 因此,样本选择方法(图像分类中最流行的解决方案之一)不适合鲁棒的 Re-ID 任务,因为有限但信息丰富的人物图像可能会被错误地删除。
行人 Re-ID 中存在两种类型的标签噪声:
样本噪声,行人图像/视频序列具有正确的身份标签,但图像包含由于检测不良/不准确的跟踪结果而导致的外围区域或异常视频帧,例如 被场景中的物体遮挡。 这个问题在文献中得到了广泛的研究。 例如,采用显着性和注意力模型来解决人物图像中的外围区域。 此外,一些方法还使用姿势/部分引导技术来处理局部杂乱区域。 对于基于视频的行人重新识别,提出了帧级重新加权和集合级特征学习来处理异常帧。
注释错误,人物图像被错误地注释为另一个身份,因为在冒名顶替者存在的情况下跨摄像机视图匹配人物即使对于人类来说也是具有挑战性的,并且在注释过程中不可避免地会出现错误。
解决方法:
为了避免拟合噪声标签,我们建议在早期阶段使用大学习率和自标签细化策略来学习预模型,其中标签和网络联合优化。 为了进一步增强鲁棒性,我们引入了具有动态相互学习功能的在线协同精炼(CORE)框架,其中网络和标签预测通过从其他对等网络中提取知识来在线协作优化。 此外,它还使用有利的选择性一致性策略减少了噪声标签的负面影响。
在本文中,我们提出了一种新颖的在线标签协同精炼框架,用于在未知标签噪声下进行稳健的人员重新识别模型学习。 基于观察到使用大学习率的深度 Re-ID 模型学习会阻止在早期阶段拟合噪声标签,我们建议首先使用大学习率和自标签细化策略学习序言模型,该模型 逐步细化带注释的标签并共同优化网络。 我们的设计避免过滤掉有限但有价值的带注释的训练样本,同时重用噪声标签。 为了增强鲁棒性,我们提出了一种通过同时学习多个对等网络的选择性在线标签共同精炼(CORE)框架。 每个网络都使用其他网络的预测输出作为训练指导进行优化。 由于每个网络都是从不同的条件初始化的,因此它们会协作学习并同时匹配它们的估计概率。 由于网络和标签预测都是在线优化的,因此具有更好的通用性和更强的鲁棒性。 此外,还引入了选择性一致性正则化策略,以减少可能错误预测的样本的负面影响,进一步保证了鲁棒性。
CORE有两个主要优点:
- 它对不同的噪声类型和未知的噪声比具有鲁棒性;
- 它可以轻松地进行训练,而无需在架构设计上做太多额外的工作。
核心思想:
在早期阶段使用较大的学习率,逐步细化错误注释的样本
问题定义:本文研究了行人重识别任务中的标签噪声问题,解决了样本噪声和标注错误。 给定一组包含未知百分比和未知类型的标签噪声的训练数据,我们的目标是学习一个强大的 Re-ID 模型,该模型可以在存在标签噪声的情况下准确地区分不同的身份。 请注意,我们不依赖任何标签噪声分布假设[11]、[23]、[25]或附加的干净注释子集[27]、[46]。 由于每个身份的带注释的训练样本非常有限,我们的基本想法是基于第 IV 节中的观察,在第 III-B 节中学习的序言模型的基础上,在早期阶段使用较大的学习率,逐步细化错误注释的样本。
baseline: 我们采用广泛使用的分类模型 ID-discriminative Embedding (IDE) 作为我们的基线模型。 在训练过程中,通过将每个身份视为不同的类别,将行人Re-ID制定为图像分类任务,并采用softmax交叉熵损失来指导网络更新。 请注意,其他训练目标也可以在我们提出的方法中与最终的细化标签无缝配置,如表六所示。 在测试阶段,行人重识别被视为图像检索任务,其中学习网络是测试图像的特征提取器,并且采用余弦相似度作为相似度度量。
交叉熵损失(CE): ,其中yi代表样本xi的注释标签。由于yi可能不正确,直接最小化上述损失会导致对错误标记样本的过度拟合(如实验部分图4所示)。
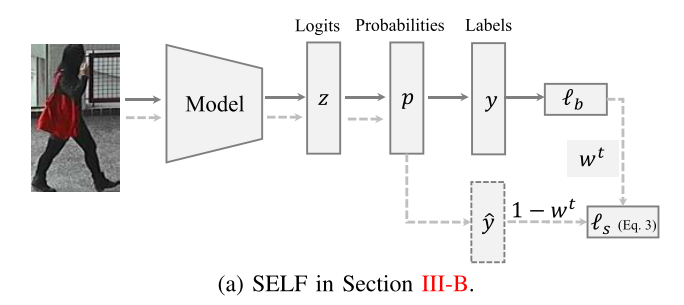
SELF:渐进式自我标签精炼
在本小节中,我们介绍了具有渐进式自标签细化策略的序言模型学习,该策略共同细化带注释的标签并优化网络。 我们的基本想法源于观察,如第 IV-B 节中所讨论的,在早期阶段使用大学习率的深度 Re-ID 模型学习可以防止拟合错误标记的样本 [64]。 基于这一观察,我们假设以大学习率学习的序言模型具有预测输入样本的真实标签的能力。 因此,可以在后期使用学习到的序言模型执行标签细化,解决错误注释。 基于上述讨论,我们的渐进自标签精炼(SELF)方法使用大学习率联合优化被识别为模型的带注释标签和预测标签的概率。
其中 yi 表示模型的预测标签。 wt 是一个渐进递减的权重参数,由每个训练时期 t 的损失 b 监督。 这种自标签细化策略逐步增加标签细化部分的贡献并减轻对b的依赖。 请注意,自标签细化学习通过随着训练次数的增加而优化网络和预测标签而成为自训练过程。 这是因为几个时期后 b 变得非常小。 预测标签{ yi }的准确率逐渐提高,网络逐渐优化。

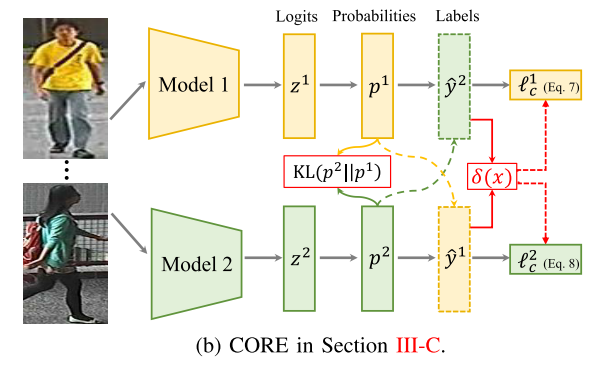
CORE:在线标签协同精炼
为了进一步增强针对错误预测标签的鲁棒性,我们提出了一种在线协同精炼(CORE)框架,通过学习两组网络,如图 2 所示。我们通过从对等网络中提取模型输出来协作更新一个网络的标签,并同时匹配两个网络之间的估计概率。 以动态更新的方式,同时在线改进行人Re-ID模型和估计标签。
给定通过上述渐进式早期自标签细化(以大学习率训练)获得的两个预定义网络 f(θ1) 和 f(θ2),我们使用 f(θ2) 的预测标签来指导训练过程 f(θ1),以较小的学习率进行微调。
KL散度:衡量两个网络估计预测之间的差异
通过这种方式,每个网络通过使用来自其对等网络的细化标签优化自身来协作学习,同时将其概率分布与其他对等网络相匹配。 以协作学习的方式,网络和预测标签都在逐步改进。 该策略重新使用错误标记的样本,而不是过滤掉它们[12]、[13]。 所提出的 CORE 的另一个好处是它独立于基线方法,当配置强大的基线骨干时,性能可以进一步提高
我们采用 ResNet50 作为我们的主干网络结构,因为它是最近 Re-ID 模型中使用最广泛的。 我们使用预先训练的 Blog-ImageNet 权重进行初始化。 我们在 pool5 层之后添加一个全连接层(维度为 512),后面是带有 ReLU 激活函数的批量归一化层,如[36]中所示。 采用随机裁剪和水平翻转进行数据增强。 首先将图像大小调整为288×144,然后随机裁剪为256×128,被馈送到网络中。 所有数据集上的训练批量大小均设置为 32。 我们采用SGD作为默认优化器,动量参数为0.9。 我们为前 20 个 epoch 设置了较大的学习率 0.1,用于带有自标签精炼的预模型学习,并为最后 40 个 epoch 将其衰减 0.1,以进行进一步的自精炼 (SELF) 或共同精炼 (CORE)。
选择性在线标签联合精炼
为了避免错误预测的负面影响,我们在 CORE 之上引入了自适应在线选择策略。 基本思想是,如果两个网络的预测一致,则该样本对整体学习功能的贡献应该被放大。
因此,采用选择性策略的 CORE 的总体损失函数定义为
实验
数据集
我们在三个公开的行人 Re-ID 数据集上进行了实验,包括 Market1501 [66]、DukeMTMC [43] 和 CUHK03 [67]。 Market1501数据集[66]包含1,501个带注释的身份,以及由6个不同相机捕获的32,668个边界框,其中边界框是由DPM检测器获得的[68]。 Duke-MTMC 数据集 [43] 是另一个大规模数据集,包含 8 个不同摄像机捕获的 1,404 个身份。 它总共包含 36,411 个手绘边界框,其中许多行人具有相似的外观。 CUHK03 数据集 [67] 包含来自两个不重叠相机的 1,467 个身份的约 14K 图像。 我们遵循[69]中描述的设置并使用检测到的版本进行评估。 三个数据集的统计数据总结在表I中。
标签噪声的产生
我们在三种不同的设置下进行实验[11]:
- 随机噪声:随机选择一定比例(10%、20%和30%)的训练图像并分配来自其他身份的错误标签。
- 模式噪声:我们首先使用干净的标签训练ResNet50基线模型,然后将一定比例的随机选择的样本分配给来自另一个身份的最相似样本的标签[11]。 这个设定比较有挑战性。
- 标准设置:我们还使用原始“干净”标签评估性能,其中包含有限的噪声(∼0%)。
评估指标
遵循现有的Re-ID工作[28],我们采用rank-k匹配精度和平均精度(mAP)作为评估指标。 Rank-k 匹配准确度表示 top-k 检索结果中出现正确匹配的概率。 mAP 表示多个真实值的平均检索性能[66]。
实施细节
我们采用 ResNet50 [72] 作为我们的主干网络结构,因为它是最近 Re-ID 模型中使用最广泛的。 我们使用预先训练的 Blog-ImageNet 权重进行初始化。 我们在 pool5 层之后添加一个全连接层(维度为 512),后面是带有 ReLU 激活函数的批量归一化层,如[36]中所示。 采用随机裁剪和水平翻转进行数据增强。 首先将图像大小调整为288×144,然后随机裁剪为256×128被馈送到网络中。 所有数据集上的训练批量大小均设置为 32。 我们采用SGD作为默认优化器,动量参数为0.9。 我们为前 20 个 epoch 设置了较大的学习率 0.1,用于带有自标签精炼的预模型学习,并为最后 40 个 epoch 将其衰减 0.1,以进行进一步的自精炼 (SELF) 或共同精炼 (CORE)。