Enhancing Robustness in Learning with Noisy Labels: An Asymmetric Co-Training Approach
一种非对称协同训练(ACT)方法,可用于减轻标签噪声的有害影响。
本文用于记录复现 ACT 在 cifar100 上的实验过程和结果,代码见 github仓库。
在 web 上的实验过程和结果可见 Enhancing Robustness in Learning with Noisy Labels: An Asymmetric Co-Training Approach 2
零、资源
操作系统配置
- 操作系统:Ubuntu20.04-桌面版
- 基础架构:GPU驱动 510.73.05、cuda 11.5
- 基础软件:miniconda 4.12.0、cudnn 8.3.0
- 基础环境:opencv、torch-1.10、tensorflow-2.6.0
- 开发工具:pycharm-community-2022.1
- 3D可视化:TurboVNC
资源配置
- 类型:RTX3090
- GPU信息:1卡 * 24GB显存
- 规格:10核 32GB内存
存储/带宽配置
- 系统存储:高效云盘 80GB
- 数据存储:高效云盘 20GB
- 网络带宽:100Mbps
一、下载代码和数据集
1.1 代码
找一个目录克隆仓库
git clone https://github.com/shtdusb/ACT1.2 数据集
CIFAR-10 和 CIFAR-100 数据集网站(打不开使用美国节点)
在 ACT 目录下执行下面命令
wget -P ./data/cifar100 https://www.cs.toronto.edu/~kriz/cifar-100-python.tar.gz如果服务器下载速度较慢,可以点击在本地下载CIFAR-10 数据集和CIFAR-100 数据集压缩包,下载完成后,上传到 ACT/data/cifar100 目录下
解压数据集
cd ./data/cifar100
tar -xzvf cifar-100-python.tar.gz解压后如图所示
二、环境配置
查看当前 cuda 版本
nvcc --version创建环境
conda env remove --name act
conda create --name act python=3.9 -y激活
conda activate act安装 Pytorch 参考Pytorch官网
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=11.8 -c pytorch -c nvidia漫长的等待后,检查 Pytorch 是否安装成功
python -c "import torch; print(torch.cuda.is_available())"输出:True
安装 act 所需依赖
pip install -r requirements.txt漫长的等待
(可选)可能会缺失以下库,可以先执行第三步看看是否缺失,按需安装
conda install tqdmpip install randaugmentpip install opencv-pythonpip install matplotlibpip install korniapip install torchmetrics # 887MB + 317MB + 557MB警告pip install easydict三、运行程序
启动!1 个 epoch 需要 40 秒,150 个 epoch 接近 100 分钟。
python main.py --gpu 0 --noise-type symmetric --closeset-ratio 0.2 --dataset cifar100nc经历了数不清的失败后,小宝贝终于跑起来了! 
更多命令可参考 六、实验结果。
可以下载 nvitop 查看占用
pip install nvitop
nvitop如果gpu占用低也不要谎,我的gpu占用只有24%,可能是模型的计算量不足,如果模型较小或计算量较少,GPU 可能并不会被充分利用。尤其是如果 batch size 很小,GPU 的并行计算能力可能无法得到完全发挥。
可以在模型训练前在 main.py 中加入下面代码查看运行设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")输出: Using device: cuda
四、遇到的问题
4.1 No module named 'data.Clothing1M'
No module named 'data.Clothing1M'
(act) root@DESKTOP-5UQUCK2:/ajohn-lab-github/ACT# python main.py --gpu 0 --noise-type symmetric --closeset-ratio 0.2 --dataset cifar100nc
Traceback (most recent call last):
File "/ajohn-lab-github/ACT/main.py", line 21, in <module>
from data.Clothing1M import *
ModuleNotFoundError: No module named 'data.Clothing1M'
(act) root@DESKTOP-5UQUCK2:/ajohn-lab-github/ACT#这里直接把 main.py 中的 from data.Clothing1M import 注释掉即可
import os
import sys
import argparse
import math
import time
import json
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
from tqdm import tqdm
from utils import *
from loss import *
from utils.builder import *
from utils.plotter import *
from model.MLPHeader import MLPHead
from util import *
from utils.eval import *
from model.ResNet32 import resnet32
from model.SevenCNN import CNN
from data.Clothing1M import *
from utils.ema import EMA
import matplotlib4.2 version 'GLIBCXX_3.4.29' not found (可能遇不到)
version 'GLIBCXX_3.4.29' not found
ImportError: /lib/x86_64-linux-gnu/libstdc++.so.6: version GLIBCXX_3.4.29' not found (required by /home/wuye/anaconda3/envs/tf2/lib/python3.8/site-packages/google/protobuf/pyext/_message.cpython-38-x86_64-linux-gnu.so)这个是默认路径下的libstdc++.so.6缺少GLIBCXX_3.4.29
使用指令先看下系统目前都有哪些版本的
strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep GLIBCXX我的只到3.4.28,所以确定是缺少GLIBCXX_3.4.29
使用指令来查看当前系统中其它的同类型文件,找到一个版本比较高的
sudo find / -name "libstdc++.so.6*"我选择的是/home/ubuntu/.conda/envs/lcnl2/lib/libstdc++.so.6.0.29,使用指令看看其是否包含3.4.29
strings /home/ubuntu/.conda/envs/lcnl2/lib/libstdc++.so.6.0.29 | grep GLIBCXX发现存在GLIBCXX_3.4.29,接下来就是建立新的链接到这个文件上
开始干活:
复制
sudo cp /home/ubuntu/.conda/envs/lcnl2/lib/libstdc++.so.6.0.29 /usr/lib/x86_64-linux-gnu/删除之前链接
sudo rm /usr/lib/x86_64-linux-gnu/libstdc++.so.6创建新的链接
sudo ln -s /home/ubuntu/.conda/envs/lcnl2/lib/libstdc++.so.6.0.29 /usr/lib/x86_64-linux-gnu/libstdc++.so.6检查
ll /usr/lib/x86_64-linux-gnu/libstd*strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep GLIBCXX参考链接:如何解决version `GLIBCXX_3.4.29‘ not found的问题
4.3 AttributeError: module 'numpy' has no attribute 'int'.
AttributeError: module 'numpy' has no attribute 'int'.
(act) ubuntu@ml-ubuntu20-04-desktop-v3-2-32gb-25m:~/ajohn-lab/ACT$ python main.py --gpu 0 --noise-type symmetric --closeset-ratio 0.2 --dataset cifar100nc
Namespace(log=None, gpu='0', seed=123, batch_size=128, lr=0.001, lr_decay='cosine:20,5e-4,100', weight_decay=0.0005, opt='sgd', warmup_epochs=20, warmup_lr=0.001, lr1=0.001, epochs=100, save_weights=False, dataset='cifar100nc', noise_type='symmetric', closeset_ratio=0.2, database='./dataset', model='CNN', ablation=False, method='ours', tau=0.025)
Available GPUs Index : 0
2024-12-04 18:35:20 - | MSG | - Result Path: CNNResults/cifar100nc/symm_20/None-20241204_183520
2024-12-04 18:35:20 - | MSG | - Namespace(log=None, gpu='0', seed=123, batch_size=128, lr=0.001, lr_decay='cosine:20,5e-4,100', weight_decay=0.0005, opt='sgd', warmup_epochs=20, warmup_lr=0.001, lr1=0.001, epochs=100, save_weights=False, dataset='cifar100nc', noise_type='symmetric', closeset_ratio=0.2, database='./dataset', model='CNN', ablation=False, method='ours', tau=0.025, openset_ratio=0.0)
Traceback (most recent call last):
File "/home/ubuntu/ajohn-lab/ACT/main.py", line 429, in <module>
loader_dict = build_loader(config)
File "/home/ubuntu/ajohn-lab/ACT/main.py", line 287, in build_loader
transform = build_transform(rescale_size=32, crop_size=32)
File "/home/ubuntu/ajohn-lab/ACT/utils/builder.py", line 70, in build_transform
CIFAR10Policy(),
File "/home/ubuntu/.conda/envs/act/lib/python3.9/site-packages/randaugment/randaugment.py", line 264, in __init__
SubPolicy(0.1, "invert", 7, 0.2, "contrast", 6, fillcolor),
File "/home/ubuntu/.conda/envs/act/lib/python3.9/site-packages/randaugment/randaugment.py", line 372, in __init__
"posterize": np.round(np.linspace(8, 4, 10), 0).astype(np.int),
File "/home/ubuntu/.conda/envs/act/lib/python3.9/site-packages/numpy/__init__.py", line 305, in __getattr__
raise AttributeError(__former_attrs__[attr])
AttributeError: module 'numpy' has no attribute 'int'.
`np.int` was a deprecated alias for the builtin `int`. To avoid this error in existing code, use `int` by itself. Doing this will not modify any behavior and is safe. When replacing `np.int`, you may wish to use e.g. `np.int64` or `np.int32` to specify the precision. If you wish to review your current use, check the release note link for additional information.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations这个错误是因为 numpy.int 已在 NumPy 1.20 版本中被弃用,并且在新的版本中已被移除。你需要修改代码中的 np.int,将其替换为 Python 内置的 int 或使用 np.int64 或 np.int32 来明确指定精度。
在 /home/ubuntu/.conda/envs/act/lib/python3.9/site-packages/randaugment/randaugment.py 找到 np.int 并修改 为 int
ranges = {
"shearx": np.linspace(0, 0.3, 10),
"sheary": np.linspace(0, 0.3, 10),
"translatex": np.linspace(0, 150 / 331, 10),
"translatey": np.linspace(0, 150 / 331, 10),
"rotate": np.linspace(0, 30, 10),
"color": np.linspace(0.0, 0.9, 10),
"posterize": np.round(np.linspace(8, 4, 10), 0).astype(np.int),
"posterize": np.round(np.linspace(8, 4, 10), 0).astype(int),
"solarize": np.linspace(256, 0, 10),
"contrast": np.linspace(0.0, 0.9, 10),
"sharpness": np.linspace(0.0, 0.9, 10),
"brightness": np.linspace(0.0, 0.9, 10),
"autocontrast": [0] * 10,
"equalize": [0] * 10,
"invert": [0] * 10,
"cutout": np.round(np.linspace(0, 20, 10), 0).astype(np.int),
"cutout": np.round(np.linspace(0, 20, 10), 0).astype(int),
}4.4 NameError: name 'DataLoader' is not defined
NameError: name 'DataLoader' is not defined
(act) ubuntu@ml-ubuntu20-04-desktop-v3-2-32gb-25m:~/ajohn-lab/ACT$ python main.py --gpu 0 --noise-type symmetric --closeset-ratio 0.2 --dataset cifar100nc
Namespace(log=None, gpu='0', seed=123, batch_size=128, lr=0.001, lr_decay='cosine:20,5e-4,100', weight_decay=0.0005, opt='sgd', warmup_epochs=20, warmup_lr=0.001, lr1=0.001, epochs=100, save_weights=False, dataset='cifar100nc', noise_type='symmetric', closeset_ratio=0.2, database='./dataset', model='CNN', ablation=False, method='ours', tau=0.025)
Available GPUs Index : 0
2024-12-04 19:18:14 - | MSG | - Result Path: CNNResults/cifar100nc/symm_20/None-20241204_191814
2024-12-04 19:18:14 - | MSG | - Namespace(log=None, gpu='0', seed=123, batch_size=128, lr=0.001, lr_decay='cosine:20,5e-4,100', weight_decay=0.0005, opt='sgd', warmup_epochs=20, warmup_lr=0.001, lr1=0.001, epochs=100, save_weights=False, dataset='cifar100nc', noise_type='symmetric', closeset_ratio=0.2, database='./dataset', model='CNN', ablation=False, method='ours', tau=0.025, openset_ratio=0.0)
Noise Transition Matrix:
[[0.8 0.0020202 0.0020202 ... 0.0020202 0.0020202 0.0020202]
[0.0020202 0.8 0.0020202 ... 0.0020202 0.0020202 0.0020202]
[0.0020202 0.0020202 0.8 ... 0.0020202 0.0020202 0.0020202]
...
[0.0020202 0.0020202 0.0020202 ... 0.8 0.0020202 0.0020202]
[0.0020202 0.0020202 0.0020202 ... 0.0020202 0.8 0.0020202]
[0.0020202 0.0020202 0.0020202 ... 0.0020202 0.0020202 0.8 ]]
Noise Type: symmetric (close set: 0.2, open set: 0.0)
Actual Total Noise Ratio: 0.201
Traceback (most recent call last):
File "/home/ubuntu/ajohn-lab/ACT/main.py", line 431, in <module>
loader_dict = build_loader(config)
File "/home/ubuntu/ajohn-lab/ACT/main.py", line 295, in build_loader
trainloader = DataLoader(dataset['train'], batch_size=params.batch_size, shuffle=True, num_workers=4,
NameError: name 'DataLoader' is not defined在 main.py 加入一行即可解决
from torch.utils.data import DataLoader五、参数解读
5.1 数据集:
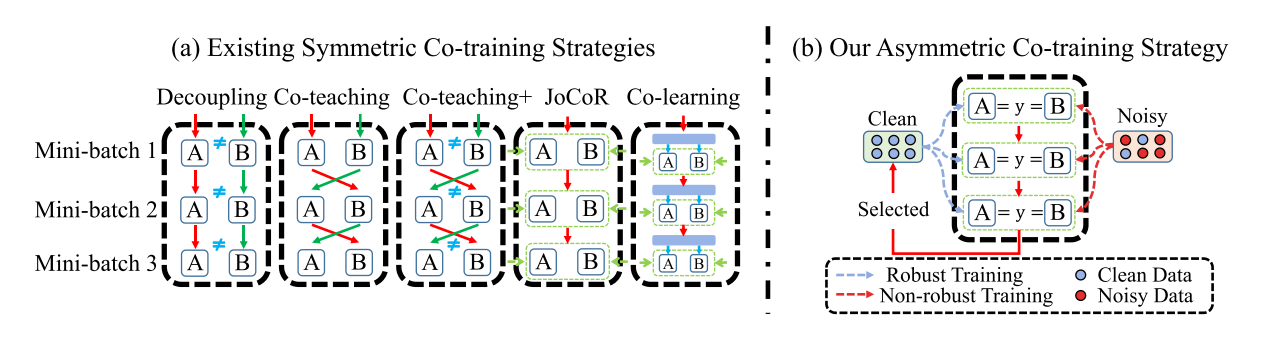
CIFAR100N 和 CIFAR80N 源自 CIFAR100。 创建它们是为了分别模拟封闭集和开放集的噪声场景。我们主要研究两种类型的合成标签噪声:对称(Sym.)和不对称(Asym.)。
真实世界数据集:Web-Aircraft、Web-Bird 和 Web-Car 是三个真实世界的噪声数据集,其训练图像为从网络图像搜索引擎抓取。 与合成数据集相比,由于其不可预测的噪声模式,它们提出了更重大的挑战。 此外,据透露,它们包含闭集和开集噪声。 Food-101N 是另一个包含 101 个食品类别的基准数据集。 它包含大约 310k 个噪声训练图像。 噪声率和结构均未知。
5.2 网络架构
训练网络 net0(干净标签的网络)即 RTM,使用lr=0.01
训练网络 net1(带有噪声标签的网络)即 NTM,使用lr1=0.08。 对于NTM,我们遵循传统的监督学习程序,对整个训练集𝐷进行训练。
显然,NTM 是预先确定的,会过度拟合噪声样本并产生退化的性能。 然而,我们的设计使 NTM 能够通过从不同角度学习的知识来补充 RTM。 具体来说,基于我们的非对称训练设计,RTM 始终从干净样本中进行稳健学习,而 NTM 由于标签记忆而逐渐适应所有样本(包括噪声样本)。 RTM 和 NTM 在学习干净样本(即鲁棒学习)时往往表现出一致,但在学习噪声样本(即标签记忆)时表现出分歧。 因此,我们认为,与现有的 SCT 方法相比,我们的不对称训练可以为选择干净样本提供更独特的见解。
合成训练数据集使用七层CNN,现实世界数据集使用resnet50
5.3 超参数:
我们使用七层CNN网络作为我们的RTM和NTM的骨干在合成数据集上进行实验。 因此,模型使用动量为 0.9 的 SGD 训练 150 个时期(包括 50 个预热时期)。 为了进一步促进两个模型之间的不对称性,我们将 RTM 和 NTM 的学习率分别设置为 0.01 和 0.08。 批量大小为 128,学习率以余弦退火方式衰减。
在对现实世界数据集进行实验时,我们利用预先训练的 ResNet50 Blog-ImageNet-1K 作为我们的骨干。 批量大小、初始学习率和权重衰减分别为 16、0.005 和 0.0005。 评估指标:我们采用测试准确性作为评估模型性能的主要指标。 此外,为了进行更全面的分析,我们还使用精度、召回率和 F1 分数指标来评估样本选择的结果。 我们报告的性能是五次重复运行的平均结果。
5.4 噪声类型
对称标签噪声:标签错误的概率是均匀的,每个类别标签被误标为其他类别的概率相同。
不对称标签噪声:标签错误的概率是有偏的,不同类别之间的错误标签转移概率不同,通常更符合实际应用中的噪声模式。
5.5 损失函数:
在预热过程中,两个网络的损失函数分别是:
- net[0]:交叉熵损失 + 正则化损失
# main.py 第 220 行 loss_ce = F.cross_entropy(logits, y) # 计算交叉熵损失 penalty = conf_penalty(logits) # 计算正则化损失 loss0 = loss_ce + penalty # 总损失(交叉熵损失 + 正则化损失)- net[1]:交叉熵损失
# main.py 第 227 行 loss1 = F.cross_entropy(logits, y) # 计算交叉熵损失在正式训练过程中,两个网络的损失函数分别是:
- net[0]:加权交叉熵损失 + 对抗训练损失
# main.py 第 170 行 loss0 = (F.cross_entropy(logits0[idx_selected], y[idx_selected], reduction="none") * ((weights[indices[idx_selected]]) / (epoch + 1))).mean() # 计算对抗训练损失 outputs_CR = net[0](x_s) logits_CR = outputs_CR['logits'] if type(outputs_CR) is dict else outputs_CR loss_CR = F.cross_entropy(logits_CR, pesudo) # 计算对抗损失(伪标签) # 综合损失:使用加权损失函数 weight = 0.8 # 加权系数 loss0 = loss0 * weight + loss_CR * (1 - weight)- net[1]:交叉熵损失
# main.py 第 172 行 loss1 = F.cross_entropy(logits1, y) # 对于net1的标准交叉熵损失
六、实验结果
重要
注:本章实验结果为本人真实实验,引用请注明出处
| CIFAR100N | CIFAR100N | CIFAR100N | CIFAR80N | CIFAR80N | CIFAR80N |
|---|---|---|---|---|---|
| Sym-20% | Sym-80% | Asym-40% | Sym-20% | Sym-80% | Asym-40% |
| 60.41 | 60.8660 | 66.3820 | / | 63.2590 |
上表展示了合成数据集(即CIFAR100N和CIFAR80N)在各种噪声类型(即对称和非对称)和噪声率(即20%、40%和80%)下的比较结果。与 CIFAR100N 相比,CIFAR80N 无疑更具挑战性,因为它是为了模拟闭集和开集噪声标签同时存在的现实世界情况而生成的。
6.1 CIFAR100N
6.1.1 Sym-20%
python main.py --gpu 0 --noise-type symmetric --closeset-ratio 0.2 --dataset cifar100nc参数如下
{
"log": null,
"gpu": "0",
"seed": 123,
"batch_size": 128,
"lr": 0.01,
"lr_decay": "cosine:20,5e-4,100",
"weight_decay": 0.0005,
"opt": "sgd",
"warmup_epochs": 50,
"warmup_lr": 0.001,
"lr1": 0.08,
"epochs": 150,
"save_weights": false,
"dataset": "cifar100nc",
"noise_type": "symmetric",
"closeset_ratio": 0.2,
"database": "./dataset",
"model": "CNN",
"ablation": false,
"method": "ours",
"tau": 0.025,
"openset_ratio": 0.0
}实验结果
valid epochs: [149, 148, 147, 146, 145, 144, 143, 142, 141, 140]
mean: 60.4700, std: 0.0933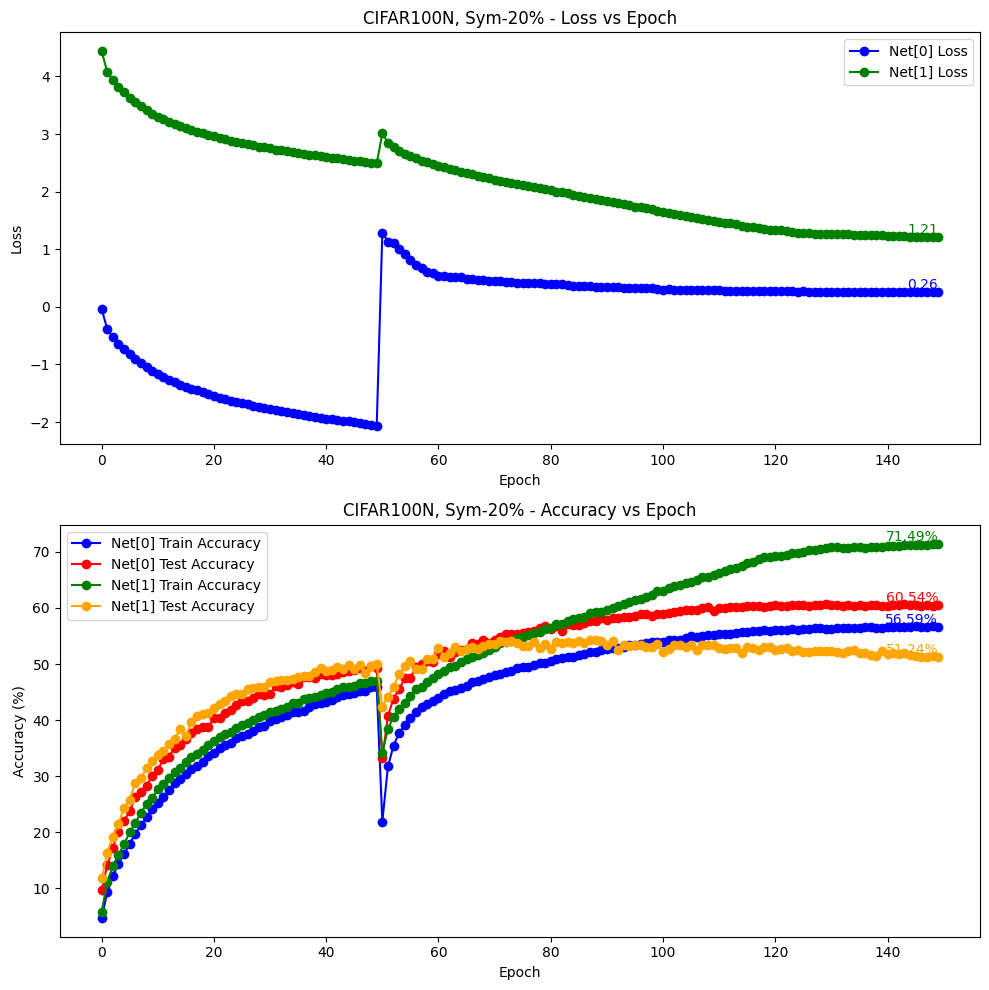
6.1.2 Sym-80%
python main.py --gpu 0 --noise-type symmetric --closeset-ratio 0.8 --dataset cifar100nc参数如下:
{
"log": null,
"gpu": "0",
"seed": 123,
"batch_size": 128,
"lr": 0.001,
"lr_decay": "cosine:20,5e-4,100",
"weight_decay": 0.0005,
"opt": "sgd",
"warmup_epochs": 20,
"warmup_lr": 0.001,
"lr1": 0.001,
"epochs": 100,
"save_weights": false,
"dataset": "cifar100nc",
"noise_type": "symmetric",
"closeset_ratio": 0.8,
"database": "./dataset",
"model": "CNN",
"ablation": false,
"method": "ours",
"tau": 0.025,
"openset_ratio": 0.0
}实验结果
valid epochs: [99, 98, 97, 96, 95, 94, 93, 92, 91, 90]
mean: 15.6170, std: 0.20686.1.3 Asym-40%
python main.py --gpu 0 --noise-type asymmetric --closeset-ratio 0.4 --dataset cifar100nc参数如下:
{
"log": null,
"gpu": "0",
"seed": 123,
"batch_size": 128,
"lr": 0.01,
"lr_decay": "cosine:20,5e-4,100",
"weight_decay": 0.0005,
"opt": "sgd",
"warmup_epochs": 50,
"warmup_lr": 0.01,
"lr1": 0.08,
"epochs": 150,
"save_weights": false,
"dataset": "cifar100nc",
"noise_type": "asymmetric",
"closeset_ratio": 0.4,
"database": "./dataset",
"model": "CNN",
"ablation": false,
"method": "ours",
"tau": 0.025,
"openset_ratio": 0.0
}实验结果:
valid epochs: [149, 148, 147, 146, 145, 144, 143, 142, 141, 140]
mean: 60.8660, std: 0.1392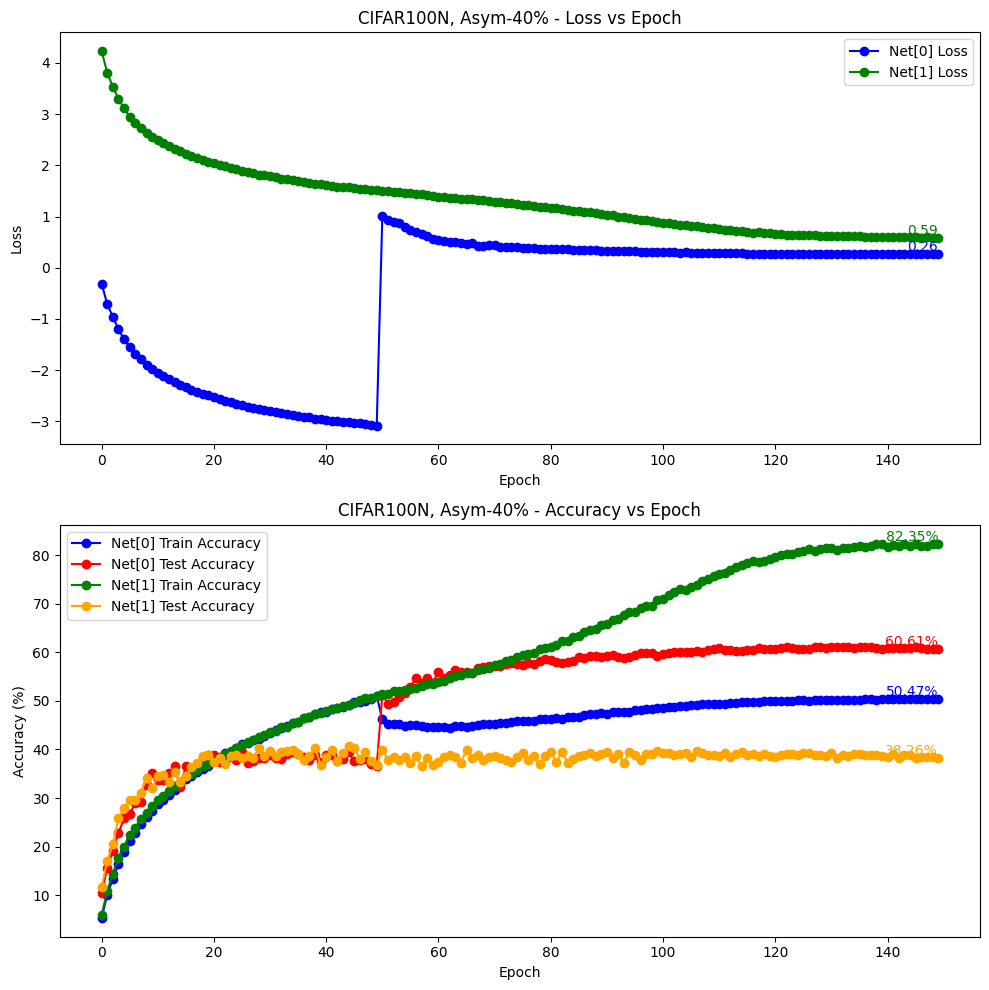
6.2 CIFAR80N
6.2.1 Sym-20%
python main.py --noise-type symmetric --closeset-ratio 0.2 --dataset cifar80no参数如下:
{
"log": null,
"gpu": "0",
"seed": 123,
"batch_size": 128,
"lr": 0.01,
"lr_decay": "cosine:20,5e-4,100",
"weight_decay": 0.0005,
"opt": "sgd",
"warmup_epochs": 50,
"warmup_lr": 0.01,
"lr1": 0.08,
"epochs": 150,
"save_weights": false,
"dataset": "cifar80no",
"noise_type": "symmetric",
"closeset_ratio": 0.2,
"database": "./dataset",
"model": "CNN",
"ablation": false,
"method": "ours",
"tau": 0.025,
"openset_ratio": 0.2
}实验结果:
valid epochs: [149, 148, 147, 146, 145, 144, 143, 142, 141, 140]
mean: 66.3820, std: 0.1444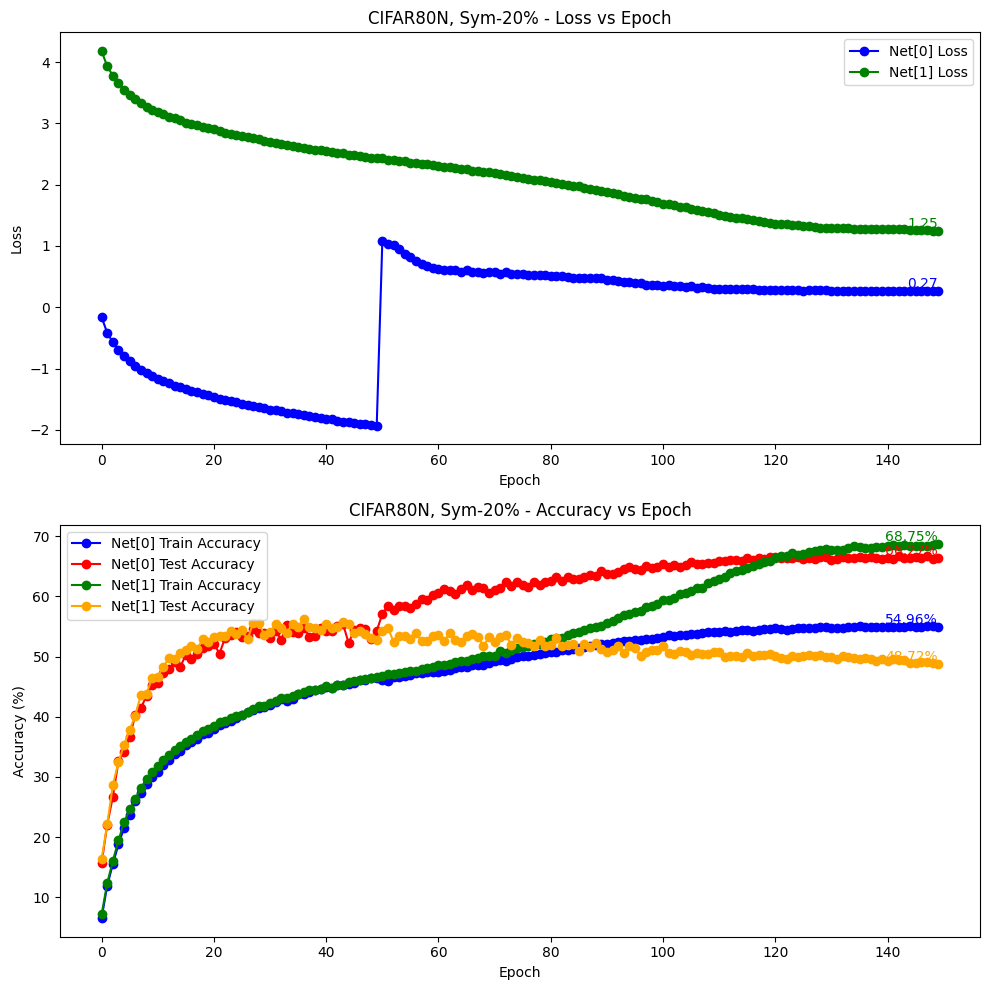
6.2.2 Sym-80%
python main.py --noise-type symmetric --closeset-ratio 0.8 --dataset cifar80no6.2.3 Asym-40%
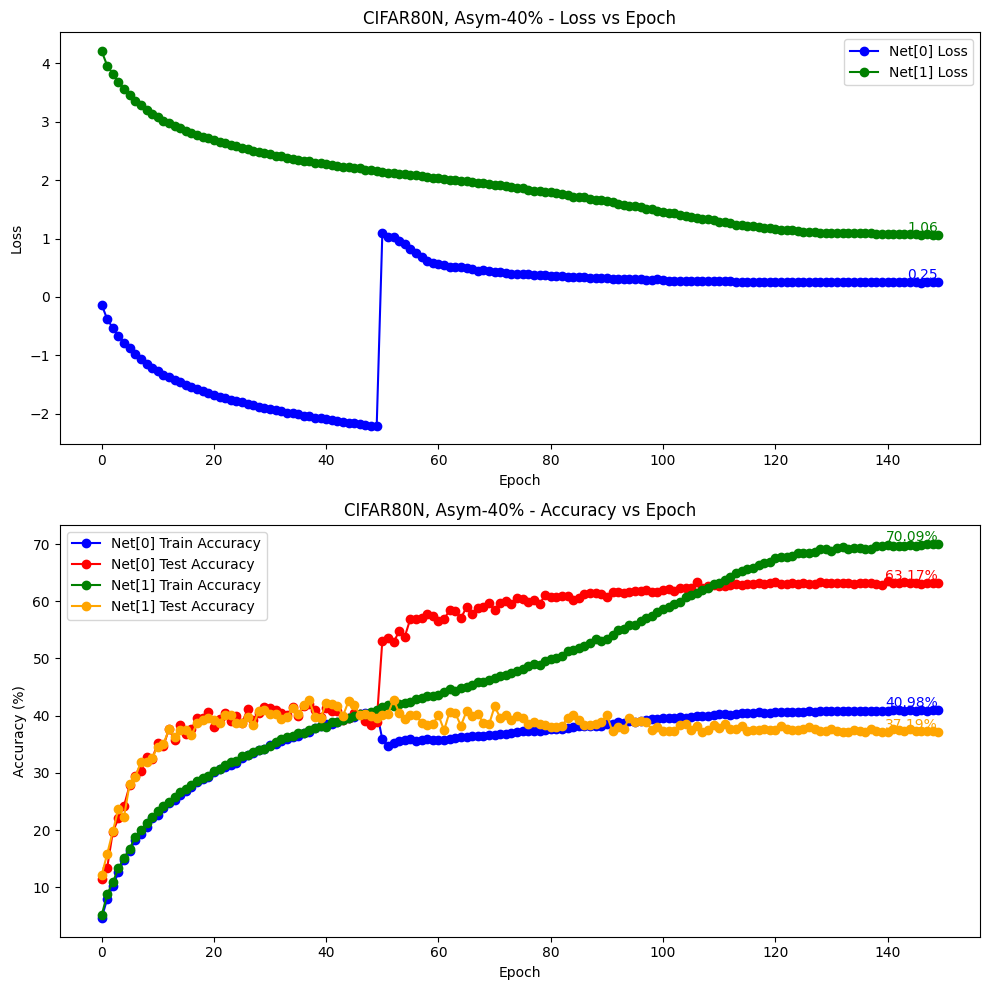
python main.py --noise-type asymmetric --closeset-ratio 0.4 --dataset cifar80no参数如下:
{
"log": null,
"gpu": "0",
"seed": 123,
"batch_size": 128,
"lr": 0.01,
"lr_decay": "cosine:20,5e-4,100",
"weight_decay": 0.0005,
"opt": "sgd",
"warmup_epochs": 50,
"warmup_lr": 0.01,
"lr1": 0.08,
"epochs": 150,
"save_weights": false,
"dataset": "cifar80no",
"noise_type": "asymmetric",
"closeset_ratio": 0.4,
"database": "./dataset",
"model": "CNN",
"ablation": false,
"method": "ours",
"tau": 0.025,
"openset_ratio": 0.2
}实验结果:
valid epochs: [149, 148, 147, 146, 145, 144, 143, 142, 141, 140]
mean: 63.2590, std: 0.1166