
《Effective STL》
《Effective STL》 - [美] Scott Meyers
引言
你已经熟悉STL了。你知道怎样创建容器、怎样遍历容器中的内容,知道怎样添加和删除元素,以及如何使用常见的算法,比如find和sort。但是你并不满意。你总是感到自己还不能充分地利用STL。本该很简单的任务却并不简单;本该很直接的操作却要么泄漏资源,要么结果不对;本该更有效的过程却需要更多的时间或内存,超出了你的预期。是的,你已经知道如何使用STL了,但是你并不能确定自己是否在有效地使用它。
本书中的信息将会使你成为一位更优秀的STL程序员;它会使你成为一位高效率、高产出的程序员;它还会使你成为一位快乐的程序员。使用STL很令人开心,但是有效地使用它则令人更开心,这种开心来源于它会使你有更多的时间离开键盘,因为你可能不相信自己会节省这么多时间。即便是对STL粗略浏览一遍,也能发现这是一个非常酷的库,但你可能想象不到实际上它还要酷得多(无论是深度还是广度)。本书的一个主要目标是向你展示这个库是多么令人惊奇,因为在我从事程序设计近三十年来,我从来没看到过可以与STL相媲美的代码库。可能你也没见过。
定义、使用和扩展STL
STL之所以存在扩展,其中一个原因是,STL的设计目的就是为了便于扩展。但在本书中,我将把焦点放在如何使用STL上,而不是如何向其中添加新的部件。比如,你会发现,我将很少讲述如何编写自己的算法,对于如何编写新的容器和迭代器也没有给出任何建议。我相信,在考虑增强STL的能力之前,首先重要的是掌握STL已经提供了什么,而这正是本书的焦点所在。
术语,术语,术语
vector、string、deque 和 list 被称为标准序列容器。标准关联容器是 set、multiset、map 和 multimap。
注
根据迭代器所支持的操作,可以把迭代器分为五类。简单来说,输入迭代器(input iterator)是只读迭代器,在每个被遍历到的位置上只能被读取一次。输出迭代器(output iterator)是只写迭代器,在每个被遍历到的位置上只能被写入一次。输入和输出迭代器的模型分别是建立在针对输入和输出流(例如文件)的读写操作的基础上的。所以不难理解,输入和输出迭代器最常见的表现形式是istream_iterator和ostream_iterator。
前向迭代器 (forward iterator)兼具输入和输出迭代器的能力,但是它可以对同一个位置重复进行读和写。前向迭代器不支持operator--,所以它只能向前移动。所有的标准STL容器都支持比前向迭代器功能更强大的迭代器,但是,你在第25条中可以看到,散列容器的一种设计会产生前向迭代器。单向链表容器(见第50条)也提供了前向迭代器。
双向迭代器 (bidirectional iterator)很像前向迭代器,只是它们向后移动和向前移动同样容易。标准关联容器都提供了双向迭代器。list也是如此。
随机访问迭代器 (random access iterator)有双向迭代器的所有功能,而且,它还提供了“迭代器算术”,即向前或向后跳跃一步的能力。vector、string和deque都提供了随机访问迭代器。指向数组内部的指针对于数组来说也是随机访问迭代器。
所有重载了函数调用操作符(即operator())的类都是一个函数子类(functor class)。从这些类创建的对象被称为函数对象(function object)或函数子(functor)。在STL中,大多数使用函数对象的地方同样也可以使用实际的函数,所以我经常使用“函数对象”(function object)这个术语既表示C++函数,也表示真正的函数对象。
函数bind1st和bind2nd被称为绑定器(binder)。
第1章 容器
第1条:慎重选择容器类型。
注
标准STL序列容器 :vector、string、deque和list。
标准STL关联容器 :set、multiset、map和multimap。
非标准序列容器slist和rope 。slist是一个单向链表,rope本质上是一“重型”string。(“rope”是重型“string”,明白了吗?)你可以在第50条中找到对这些非标准(但通常可以使用)的容器的一个简要介绍。
非标准关联容器hash_set、hash_multiset、hash_map和hash_multimap 。在第25条中,我分析了这些基于散列表的、标准关联容器的变体(它们通常是广泛可用的)。
vector<char>作为string的替代 。第13条讲述了在何种条件下这种替代是有意义的。vector作为标准关联容器的替代 。正如第23条中所阐明的,有时vector在运行时间和空间上都要优于标准关联容器。
几种标准的非STL容器 ,包括数组、bitset、valarray、stack、queue和priority_queue。因为它们不是STL容器,所以在本书中很少提及,仅在第16条中提到了一种“数组优于STL容器”的情形,以及在第18条中解释了为什么bitset比
vector<bool>要好。值得记住的是,数组也可以被用于STL算法,因为指针可以被用作数组的迭代器。
提示
对于容器,STL给了你多种选择。在STL以外,你还有更多的选择。在选择一个容器之前,请仔细考虑所有的选择。存在“默认的容器”吗?我可不这样认为。
第2条:不要试图编写独立于容器类型的代码。
即便是最热心地倡导独立于容器类型的代码的人也很快会意识到,试图编写对序列容器和关联容器都适用的代码几乎是毫无意义的。很多成员函数仅当其容器为某一种类型时才存在,例如,只有序列容器才支持push_front或push_back,只有关联容器才支持count和lower_bound,等等。即使是insert和erase这样的基本操作,也会随容器类型的不同而表现出不同的原型和语义。
面对现实吧:这么做不值得。不同的容器是不同的,它们有非常明显的优缺点。
它们并不是被设计来交换使用的,你无法掩盖这一点。如果你试图这样做,你只是在碰运气,而这种运气却是碰不到的。
第3条:确保容器中的对象副本正确而高效。
容器中保存了对象,但并不是你提供给容器的那些对象。而当从容器中取出一个对象时,你所取出的也并不是容器中所保存的那份。当向容器中加入对象时(通过如insert或push_back之类的操作),存入容器的是你所指定的对象的副本。当(通过如front或back之类的操作)从容器中取出一个对象时,你所得到的是容器中所保存的对象的副本。进去的是副本,出来的也是副本(copy in,copy out)。这就是STL的工作方式。
当然,在存在继承关系的情况下,复制动作会导致剥离(slicing)。也就是说,如果你创建了一个存放基类对象的容器,却向其中插入派生类的对象,那么在派生类对象(通过基类的复制构造函数)被复制进容器时,它所特有的部分(即派生类中的信息)将会丢失。“剥离”问题意味着向基类对象的容器中插入派生类对象几乎总是错误的。如果你希望插入后的对象仍然表现得像派生类对象一样,例如调用派生类的虚函数等,那么这种期望是错误的。
使复制动作高效、正确,并防止剥离问题发生的一个简单办法是使容器包含指针而不是对象。也就是说,使用Widget* 的容器,而不是Widget的容器。复制指针的速度非常快,并且总是会按你期望的方式进行(它复制构成指针的每一位),而且当它被复制时不会有任何剥离现象发生。不幸的是,指针的容器也有其自身的一些令人头疼的、与STL相关的问题。你可以参考第7条和第33条。如果你想避开这些使人头疼的问题,同时又想避免效率、正确性和剥离这些问题,你可能会发现智能指针(smart pointer)是一个诱人的选择。要想了解更多关于这种选择的知识,请参阅第7条。
提示
与数组相比,STL容器要聪明得多。你让它创建多少对象,它就(通过复制)创建多少对象,不会多,也不会少。你让它创建时它才创建,只有当你让它使用默认构造函数时它才会使用。没错,STL容器是在创建副本;确实是这样的,你需要明白这一点。但是,跟数组相比,它们仍是迈出了一大步。这是一个不可忽略的事实
第4条:调用empty而不是检查size()是否为0。
对任一容器c,下面的代码 if(c.size()== 0) 本质上与 if (c.empty()) 是等价的。既然如此,你或许会疑惑为什么要偏向于某一种形式,尤其是考虑到empty通常被实现为内联函数(inline function),并且它所做的仅仅是返回size是否为0。
你应该使用empty形式,理由很简单:empty对所有的标准容器都是常数时间操作,而对一些list实现,size耗费线性时间。
提示
不管发生了什么,调用empty而不是检查size==0是否成立总是没错的。所以,如果你想知道容器中是否含有零个元素,请调用empty。
第5条:区间成员函数优先于与之对应的单元素成员函数。
设计该小测验的第二个目的是为了揭示为什么区间成员函数(range member function)优先于与之对应的单元素成员函数。区间成员函数是指这样的一类成员函数,它们像STL算法一样,使用两个迭代器参数来确定该成员操作所执行的区间。如果不使用区间成员函数来解决本条款开篇时提出的问题,你就得写一个显式的循环。
太多的STL程序员滥用了copy,所以我刚才给出的建议值得再重复一下:通过利用插入迭代器的方式来限定目标区间的copy调用,几乎都应该被替换为对区间成员函数的调用。
注
现在回到assign的例子。我们已经给出了使用区间成员函数而不是其相应的单元素成员函数的原因:
通过使用区间成员函数,通常可以少写一些代码。
使用区间成员函数通常会得到意图清晰和更加直接的代码。
效率分析
第一种影响是不必要的函数调用。把numValues个元素逐个插入到v中导致了对insert的numValues次调用。而使用区间形式的insert,则只做了一次函数调用,节省了numValues-1次。当然,使用内联(inlining)可能会避免这样的影响,但是,实际中不见得会使用内联。只有一点是肯定的:使用区间形式的insert,肯定不会有这样的影响。
内联无法避免第二种影响,即把v中已有的元素频繁地移动到插入后它们所处的位置。每次调用insert把新元素插入到v中时,插入点后的每个元素都要向后移动一个位置,以便为新元素腾出空间。所以,位置p的元素必须被移动到位置p+l,等等。在我们的例子中,我们向v的前端插入numValues个元素,这意味着v中插入点之后的每个元素都要向后移动numValues个位置。每次调用insert时,每个元素需向后移动一个位置,所以每个元素将移动numValues次。如果插入前v中有n个元素,就会有n* numValues次移动。在这个例子中,v中存储的是int类型,每次移动最终可能会归为调用memmove,可是如果v中存储的是Widget这样的用户自定义类型,则每次移动会导致调用该类型的赋值操作符或复制构造函数。(大多数情况下会调用赋值操作符,但每次vector中的最后一个元素被移动时,将会调用该元素的复制构造函数。)所以在通常情况下,把numValues个元素逐个插入到含有n个元素的vector<Widget>的前端将会有n* numValues次函数调用的代价:(n-1)* numValues次调用Widget的赋值操作符和numValues次调用Widget的复制构造函数。即使这些调用是内联的,你仍然需要把v中的元素移动numValues次。
与此不同的是,C++标准要求区间insert函数把现有容器中的元素直接移动到它们最终的位置上,即只需付出每个元素移动一次的代价。总的代价包括n次移动、numValues次调用该容器中元素类型的复制构造函数,以及调用该类型的赋值操作符。同每次插入一个元素的策略相比较,区间insert减少了n* (numValues-1)次移动。细算下来,这意味着如果numValues是100,那么区间形式的insert比重复调用单元素形式的insert减少了99%的移动。
在讲述单元素形式的成员函数和与其对应的区间成员函数相比较所存在的第三个效率问题之前,我需要做一个小小的更正。我在前面的段落中所写的是对的,的确是对的,但并不总是对的。区间insert函数仅当能确定两个迭代器之间的距离而不会失去它们的位置时,才可以一次就把元素移动到其最终位置上。这几乎总是可能的,因为所有的前向迭代器都提供了这样的功能,而前向迭代器几乎无处不在。标准容器的所有迭代器都提供了前向迭代器的功能。非标准散列容器的迭代器也是如此(见第25条)。指针作为数组的迭代器也提供了这一功能。实际上,不提供这一功能的标准迭代器仅有输入和输出迭代器。所以,我所说的是正确的,除非传入区间形式insert的是输入迭代器(如istream_iterator,见第6条)。仅在这样的情况下,区间insert也必须把元素一步步移动到其最终位置上,因而它的优势就丧失了。(对于输出迭代器不会产生这个问题,因为输出迭代器不能用来标明一个区间。)
不明智地使用重复的单元素插入操作而不是一次区间插入操作,这样所带来的最后一个性能问题跟内存分配有关,尽管它同时还伴有讨厌的复制问题。在第14条将会指出,如果试图把一个元素插入到vector中,而它的内存已满,那么vector将分配具有更大容量(capacity)的新内存,把它的元素从旧内存复制到新内存中,销毁旧内存中的元素,并释放旧内存。然后它把要插入的元素加入进来。第14条还解释了多数vector实现每次在内存耗尽时,会把容量加倍,因此,插入numValues个新元素最多可导致log<sub>2</sub>numValues次新的内存分配。第14条指出,表现出这种行为的vector实现是存在的,因此,把1000个元素逐个插入可能会导致10次新的内存分配(包括低效的元素复制)。与之对应(而且,到现在为止也可以预见),使用区间插入的方法,在开始插入前可以知道自己需要多少新内存(假定给它的是前向迭代器),所以不必多次重新分配vector的内存。可以想见,这一节省是很可观的。
提示
现在你明白了,优先选择区间成员函数而不是其对应的单元素成员函数有三条充分的理由:区间成员函数写起来更容易,更能清楚地表达你的意图,而且它们表现出了更高的效率。这是很难被打败的三驾马车。
第6条:当心C++编译器最烦人的分析机制。
注
list<int> data(istream iterator<int>(dataFile), istream_iterator<int>()); //小心!结果不会是你所想象的那样请你注意了。这声明了一个函数data,其返回值是list<int>。这个data函数有两个参数:
第一个参数的名称是dataFile。它的类型是
istream_iterator<int>。dataFile两边的括号是多余的,会被忽略。第二个参数没有名称。它的类型是指向不带参数的函数的指针,该函数返回一个
istream_iterator<int>。
这令人吃惊,对吧?但它却与C++中的一条普遍规律相符,即尽可能地解释为函数声明。
注
所有这些都很有意思(通过它自己的歪曲的方式),但这并不能帮助我们做自己想做的事情。我们想用文件的内容初始化list<int>对象。现在我们已经知道必须绕过某一种分析机制,剩下的事情就简单了。把形式参数的声明用括号括起来是非法的,但给函数参数加上括号却是合法的,所以通过增加一对括号,我们强迫编译器按我们的方式来工作:
list<int> data((istream iterator<int>(dataFile)), istream_iterator<int>()); //注意list构造函数的第一参数两边的括号注
更好的方式是在对data的声明中避免使用匿名的istream_iterator对象(尽管使用匿名对象是一种趋势),而是给这些迭代器一个名称。下面的代码应该总是可以工作的:
ifstream dataFile("ints.dat");
istream_iterator<int> dataBegin(dataFile);
istream_iterator<int> dataEnd;
list<int> data(dataBegin, dataEnd);提示
使用命名的迭代器对象与通常的STL程序风格相违背,但你或许觉得为了使代码对所有编译器都没有二义性,并且使维护代码的人理解起来更容易,这一代价是值得的。
第7条:如果容器中包含了通过new操作创建的指针,切记在容器对象析构前将指针delete掉。
STL中的容器相当“聪明”。它们提供了迭代器,以便进行向后和向前的遍历(通过begin、end、rbegin等);它们告诉你所包含的元素类型(通过它们的value_type类型定义);在插入和删除的过程中,它们自己进行必要的内存管理;它们报告自己有多少对象,最多能容纳多少对象(分别通过size和max_size);当然,当它们自身被析构时,它们自动析构所包含的每个对象。
有了这么“聪明”的容器,许多程序员不再考虑自己做善后清理工作。更糟的是,他们认为,容器会考虑为他们做这些事情。很多情况下,他们是对的。但当容器包含的是通过new的方式而分配的指针时,他们这么想就不正确了。没错,指针容器在自己被析构时会析构所包含的每个元素,但指针的“析构函数”不做任何事情!它当然也不会调用delete。
提示
永远都不要错误地认为:你可以通过创建auto_ptr的容器使指针被自动删除。这个想法很可怕,也很危险。我将在第8条中解释为什么你应该避免这样做。
你所要记住的是:STL容器很智能,但没有智能到知道是否该删除自己所包含的指针的程度。当你使用指针的容器,而其中的指针应该被删除时,为了避免资源泄漏,你必须或者用引用计数形式的智能指针对象(比如Boost的shared_ptr)代替指针,或者当容器被析构时手工删除其中的每个指针。
最后,可能你会想到,既然像DeleteObject这样的结构能使指针容器(其中的指针指向有效的对象)避免资源泄漏更加容易,那么,创建一个类似的DeleteArray结构,对于元素为指向数组的指针的容器,使它们避免资源泄漏也应该是可能的。这当然是可能的,但是否可取则是另一回事。第13条解释了为什么动态分配的数组几乎总是不如vector和string对象。所以在坐下来写DeleteArray前,先看看第13条。或许你会发现你永远也不会用到DeleteArray结构。
第8条:切勿创建包含auto_ptr的容器对象。
现在我先说它的一个缺点。理解这一缺点不需要auto_ptr的知识,甚至不需要容器的知识:COAP是不可移植的。它怎么可以移植呢?C++标准都禁止它,好的STL平台已经做到了这一点。有理由相信,随着时间的推进,现在没有在这一点上支持标准的STL平台将会变得更加符合标准,那时,使用COAP的代码将变得比现在更加不可移植。如果你看重可移植性(你应该这样),就应该放弃COAP,因为它们不能通过可移植性测试。
或许你对可移植性不太关心。如果是这样,那我就告诉你复制auto_ptr意味着什么,这会很特别——有些人会说很古怪。当你复制一个auto_ptr时,它所指向的对象的所有权被移交到拷入的auto_ptr上,而它自身被置为NULL。你理解得对,复制一个auto_ptr意味着改变它的值。
提示
如果你的目标是包含智能指针的容器,这并不意味着你要倒霉。包含智能指针的容器是没有问题的,第50条中会指出你能找到在STL容器中工作得很好的智能指针。问题的根源只是在于auto_ptr不是这样的智能指针。它根本就不是!
第9条:慎重选择删除元素的方法。
注
如果你有一个连续内存的容器(vector、deque或string——见第1条),那么最好的办法是使用erase-remove习惯用法(见第32条):
c.erase(remove(c.begin(), c.end(), 1963), c.end()); //当c是vector、string或deque时,erase-remove习惯用法是删除特定值的元素的最好办法对list,这一办法同样适用。但正如第44条所指出的,list的成员函数remove更加有效:
c.remove(1963); //当c是list时,remove成员函数//是删除特定值的元素的最好办法。当c是标准关联容器(例如set、multiset、map或multimap)时,使用任何名为remove的操作都是完全错误的。这样的容器没有名为remove的成员函数,使用remove算法可能会覆盖容器的值(见第32条),同时可能会破坏容器。(细节请参考第22条,那里解释了为什么试图对map和multimap使用remove不能编译,而试图对set和multiset使用remove时可能编译通不过。)
对于关联容器,解决问题的正确方法是调用erase:
c.erase(1963); //当c是标准关联容器时,erase成员函数是删除特定值元素的最好办法。这样做不仅是正确的,而且是高效的,只需要对数时间开销。(对序列容器的基于remove的技术需要线性时间。)而且,关联容器的erase成员函数还有另外一个优点,即它是基于等价(equivalence)而不是相等(equality)的,这一区别的重要性将在第19条中解释。
现在给我们带来麻烦的是vector、string和deque。我们不能再使用erase-remove习惯用法了,因为没办法使erase或remove向日志文件中写信息。而且我们不能使用刚才为关联容器设计的循环,因为对vector、string和deque,它会导致不确定的行为!记住,对这类容器,调用erase不仅会使指向被删除元素的迭代器无效,也会使被删除元素之后的所有迭代器都无效。在我们的例子中,这包括i之后的所有迭代器。采用i++、++i或你所能想象得出的其他形式都无济于事,因为它们都会导致迭代器无效。
提示
要删除容器中有特定值的所有对象:
如果容器是vector、string或deque,则使用erase-remove习惯用法。
如果容器是list,则使用list::remove。
如果容器是一个标准关联容器,则使用它的erase成员函数。
要删除容器中满足特定判别式(条件)的所有对象:
如果容器是vector、string或deque,则使用erase-remove_if习惯用法。
如果容器是list,则使用list::remove_if。
如果容器是一个标准关联容器,则使用remove_copy_if和swap,或者写一个循环来遍历容器中的元素,记住当把迭代器传给erase时,要对它进行后缀递增。
要在循环内部做某些(除了删除对象之外的)操作:
如果容器是一个标准序列容器,则写一个循环来遍历容器中的元素,记住每次调用erase时,要用它的返回值更新迭代器。
如果容器是一个标准关联容器,则写一个循环来遍历容器中的元素,记住当把迭代器传给erase时,要对迭代器做后缀递增。
第10条:了解分配子(allocator)的约定和限制。
提示
乌拉!我们对分配子特性的研究终于结束了。现在让我们总结一下如果你希望编写自定义的分配子,都需要记住哪些内容:
你的分配子是一个模板,模板参数T代表你为它分配内存的对象的类型。
提供类型定义pointer和reference,但是始终让pointer为T* ,reference为T&。
千万别让你的分配子拥有随对象而不同的状态(per-object state)。通常,分配子不应该有非静态的数据成员。
记住,传给分配子的allocate成员函数的是那些要求内存的对象的个数,而不是所需的字节数。同时要记住,这些函数返回T* 指针(通过pointer类型定义),即使尚未有T对象被构造出来。
一定要提供嵌套的rebind模板,因为标准容器依赖该模板。
第11条:理解自定义分配子的合理用法。
提示
正如这些例子所显示的,分配子在许多场合下都非常有用。只要你遵守了同一类型的分配子必须是等价的这一限制要求,那么,当你使用自定义的分配子来控制通用的内存管理策略的时候,或者在聚集成员关系的时候,或者在使用共享内存和其他特殊堆的时候,就不会陷入麻烦。
第12条:切勿对STL容器的线程安全性有不切实际的依赖。
因为Lock对象在其析构函数中释放容器的互斥体,所以很重要的一点是,当互斥体应该被释放时Lock就要被析构。为了做到这一点,我们创建了一个新的代码块(block),在其中定义了Lock,当不再需要互斥体时就结束该代码块。看起来好像是我们把“调用releaseMutexFor”这一任务换成了“结束代码块”,事实上这种说法是不确切的。如果我们忘了为Lock创建新的代码块,则互斥体仍然会被释放,只不过会晚一些——当控制到达包含Lock的代码块末尾时。而如果我们忘记了调用releaseMutexFor,那么我们永远也不会释放互斥体。
而且,基于Lock的方案在有异常发生时也是强壮的。C++保证,如果有异常被抛出,局部对象会被析构,所以,即便在我们使用Lock对象的过程中有异常抛出,Lock仍会释放它所拥有的互斥体(已经证实存在一个漏洞。如果根本没有捕获异常,那么程序将终止。在这种情况下,局部对象(如lock)可能还没有调用它们的析构函数。有些编译器会这样,有些编译器不会这样,这两种情况都是有效的) 。如果我们依赖于手工调用getMutexFor和releaseMutexFor,那么,当在调用getMutexFor之后而在调用releaseMutexFor之前有异常被抛出时,我们将永远也无法释放互斥体。
提示
异常和资源管理虽然很重要,但它们不是本条款的主题。本条款是讲述STL中的线程安全性的。当涉及STL容器和线程安全性时,你可以指望一个STL库允许多个线程同时读一个容器,以及多个线程对不同的容器做写入操作。你不能指望STL库会把你从手工同步控制中解脱出来,而且你不能依赖于任何线程支持。
第2章 vector和string
第13条:vector和string优先于动态分配的数组。
每次当你发现自己要动态地分配一个数组时(例如想写"new T[...]"时),你都应该考虑用vector和string来代替。(一般情况下,当T是字符类型时用string,否则用vector。不过在本条款中,我们还会见到一种特殊的情形,在这种情形下,vector<char>可能是一种更为合理的选择。)vector和string消除了上述的负担,因为它们自己管理内存。当元素被加入到容器中时,它们的内存会增长;而当vector或string被析构时,它们的析构函数会自动析构容器中的元素并释放包含这些元素的内存。
提示
总结起来很简单,如果你正在动态地分配数组,那么你可能要做更多的工作。为了减轻自己的负担,请使用vector或string。
第14条:使用reserve来避免不必要的重新分配。
注
reserve成员函数能使你把重新分配的次数减少到最低限度,从而避免了重新分配和指针/迭代器/引用失效带来的开销。但是,在解释reserve怎样做到这一点之前,我将简单概括一下4个相互关联,但有时会被混淆的成员函数。在标准容器中,只有vector和string提供了所有这4个函数。
size()告诉你该容器中有多少个元素。它不会告诉你该容器为自己所包含的元素分配了多少内存。
capacity()告诉你该容器利用已经分配的内存可以容纳多少个元素。这是容器所能容纳的元素总数,而不是它还能容纳多少个元素。如果你想知道一个vector有多少未被使用的内存,你就得从capacity()中减去size()。如果size和capacity返回同样的值,就说明容器中不再有剩余空间了,因此下一个插入操作(通过insert或push_back等)将导致上面所讲过的重新分配过程。
resize(Container::size_type n)强迫容器改变到包含n个元素的状态。在调用resize之后,size将返回n。如果n比当前的大小(size)要小,则容器尾部的元素将会被析构。如果n比当前的大小要大,则通过默认构造函数创建的新元素将被添加到容器的末尾。如果n比当前的容量要大,那么在添加元素之前,将先重新分配内存。
reserve(Container::size_type n)强迫容器把它的容量变为至少是n,前提是n不小于当前的大小。这通常会导致重新分配,因为容量需要增加。(如果n比当前的容量小,则vector忽略该调用,什么也不做;而string则可能把自己的容量减为size()和n中的最大值,但是string的大小肯定保持不变。以我的经验,使用reserve从string中除去多余的容量通常不如使用“swap技巧”。“swap技巧”是第17条的主题。)
提示
回到本条款的要点上。通常有两种方式来使用reserve以避免不必要的重新分配。第一种方式是,若能确切知道或大致预计容器中最终会有多少元素,则此时可使用reserve。在这种情况下,就像上面代码中的vector一样,你可以简单地预留适当大小的空间。第二种方式是,先预留足够大的空间(根据你的需要而定),然后,当把所有数据都加入以后,再去除多余的容量。要去除多余部分并不困难,但在这里我不想指出如何做,因为这其中有一个诀窍。要想学习这个诀窍,请参阅第17条。
第15条:注意string实现的多样性。
注
很明显,string的实现比乍看上去有更多的自由度;同样明显的是,不同的实现以不同的方式利用了这种设计上的灵活性。这些区别总结如下:
string的值可能会被引用计数,也可能不会。很多实现在默认情况下会使用引用计数,但它们通常提供了关闭默认选择的方法,往往是通过预处理宏来做到这一点。第13条给出了你想将其关闭的一种特殊情况,但其他的原因也可能会让你这样做。比如,只有当字符串被频繁复制时,引用计数才有用,而有些应用并不经常复制内存,这就不值得使用引用计数了。
string对象大小的范围可以是一个char* 指针的大小的1倍到7倍。
创建一个新的字符串值可能需要零次、一次或两次动态分配内存。
string对象可能共享,也可能不共享其大小和容量信息。
string可能支持,也可能不支持针对单个对象的分配子。
不同的实现对字符内存的最小分配单位有不同的策略。
提示
请不要误解我的意思。我认为string是标准库中最重要的部分之一,我鼓励你多使用它。比如,第13条就是讲述为什么你应该使用string来代替动态分配的字符数组。同时,如果你想有效地使用STL,那么,你需要知道string实现的多样性,尤其是当你编写的代码必须要在不同的STL平台上运行而你又面临着严格的性能要求的时候。而且,string看起来是这么简单,而谁又能想到它的实现会这么有趣呢?
第16条:了解如何把vector和string数据传给旧的API。
注
对于
vector<int> v;表达式v[0]给出了一个引用,它是该矢量中的第一个元素,所以&v[0]是指向第一个元素的指针。C++标准要求vector中的元素存储在连续的内存中,就像数组一样。所以,如果我们希望把v传给一个如下所示的C API:
void doSomething(const int* plnts, size t numInts):那我们可以这样做:
doSomething(&v[0], v.size());这样或许能行。可能不会出错。唯一麻烦的地方在于,v可能是空的。如果是这样,那么v.size()会是零,&v[0]则试图产生一个指针,而该指针指向的东西并不存在。这可不好。这样的结果是不确定的。安全一点的方式是:
if (!v.empty()) {
doSomething(&v[0], v.size())
};在一个错误的环境中,你可能会遇到一些可疑的人,他们告诉你用v.begin()来代替&v[0],因为(这些讨厌的人会告诉你)begin返回vector的迭代器,而对于vector来说,迭代器实际上就是指针。通常这是正确的,但正如第50条所指出的那样,事实并不总是这样的,你不应该依赖于这一点。begin的返回值是一个迭代器,不是指针;当你需要一个指向vector中的数据的指针时,你永远不应该使用begin。如果为了某种原因你决定用v.begin(),那么请使用&* v.begin(),因为这和&v[0]产生同样的指针,只是你要敲入更多的字符,而且别人想理解你的代码会更加困难。坦率地讲,如果你周围的人都告诉你使用v.begin()而不是&v[0],那么,你应该重新考虑你周围的环境是否合适了。
这种得到容器中数据指针的方式对于vector是适用的,但对于string却是不可靠的。因为:(1)string中的数据不一定存储在连续的内存中;(2)string的内部表示不一定是以空字符结尾的。这也正说明了为什么在string中存在成员函数c_str。c_str函数返回一个指向字符串的值的指针,而且该指针可用于C。因此,我们可以把一个字符串s传给下面的函数:
void doSomething(const char* pString);doSomething(s.c_str());即使字符串的长度是零,这样做也是可以的。在这种情况下,c_str会返回一个指向空字符的指针。对字符串内部有空字符的情况也是可以的。但是,在这种情况下,doSomething会把内部的第一个空字符当作结尾的空字符。string对象中包含空字符没关系,但是对基于char* 的C API则不行。
第17条:使用“swap技巧”除去多余的容量。
注
按下面的做法,你可以从contestants矢量中除去多余的容量:
vector<Contestant>(contestants).swap(contestants);表达式vector<Contestant>(contestants)创建一个临时的矢量,它是contestants的副本:这是由vector的复制构造函数来完成的。然而,vector的复制构造函数只为所复制的元素分配所需要的内存,所以这个临时矢量没有多余的容量。然后我们把临时矢量中的数据和contestants中的数据做swap操作,在这之后,contestants具有了被去除之后的容量,即原先临时变量的容量,而临时变量的容量则变成了原先contestants臃肿的容量。到这时(在语句结尾),临时矢量被析构,从而释放了先前为contestants所占据的内存。乌拉!shrink-to-fit。
注
作为题外话,swap技巧的一种变化形式可以用来清除一个容器,并使其容量变为该实现下的最小值。只要与一个用默认构造函数创建的vector或string做交换(swap)就可以了:
vector<Contestant> v;
string s; //使用v和s
vector<Contestant>().swap(v); //清除v并把它的容量变为最小
string().swap(s); //清除s并把它的容量变为最小提示
关于swap技巧,或者关于一般性的swap,我最后再说一句。在做swap的时候,不仅两个容器的内容被交换,同时它们的迭代器、指针和引用也将被交换(string除外)。在swap发生后,原先指向某容器中元素的迭代器、指针和引用依然有效,并指向同样的元素——但是,这些元素已经在另一个容器中了。
第18条:避免使用vector<bool>。
注
作为一个STL容器,vector<bool>只有两点不对。首先,它不是一个STL容器。其次,它并不存储bool。除此以外,一切正常。
一个对象并不因为有人说它是一个STL容器,所以它就是了。一个对象要成为STL容器,就必须满足C++标准的第23.1节列出的所有条件。其中的一个条件是,如果c是包含对象T的容器,而且c支持operator[],那么下面的代码必须能够被编译:
T *p = &c[0]; //用operator[]返回的变量的地址初始化一个T*变量换句话说,如果你用operator[]取得了Container<T>中的一个T对象,那么你可以通过取它的地址得到一个指向该对象的指针。(这里假定T没有用非常规的方式对operator&做重载。)所以,如果vector<bool>是一个容器,那么下面这段代码必须可以被编译:
vector<bool>; //用vector<bool>::operator[]返回的
bool *pb = &v[0]; //变量的地址初始化一个bool*变量但是它不能编译。不能编译的原因是,vector<bool>是一个假的容器,它并不真的储存bool,相反,为了节省空间,它储存的是bool的紧凑表示。在一个典型的实现中,储存在“vector”中的每个“bool”仅占一个二进制位,一个8位的字节可容纳8个“bool”。在内部,vector<bool>使用了与位域(bitfield)一样的思想,来表示它所存储的那些bool;实际上它只是假装存储了这些bool。
标准库提供了两种选择,可以满足绝大多数情况下的需求。第一种是deque<bool>。deque几乎提供了vector所提供的一切(可以看到的省略只有reserve和capacity),但deque<bool>是一个STL容器,而且它确实存储bool。当然,deque中元素的内存不是连续的,所以你不能把deque<bool>中的数据传递给一个期望bool数组的C API 〔1〕 (见第16条),但对于vector<bool>,你也不能这么做,因为没有一种可移植的方法能够得到vector<bool>的数据。(第16条中针对vector的技术对于vector<bool>不能通过编译,因为它们要求能得到一个指向vector中所含元素类型的指针。我不是已经提到过vector<bool>中并没有存储bool吗?)
第二种可以替代vector<bool>的选择是bitset。bitset不是STL容器,但它是标准C++库的一部分。与STL容器不同的是,它的大小(即元素的个数)在编译时就确定了,所以它不支持插入和删除元素。而且,因为它不是一个STL容器,所以它不支持迭代器。但是,与vector<bool>一样,它使用了一种紧凑表示,只为所包含的每个值提供一位空间。它提供了vector<bool>特有的flip成员函数,以及其他一些特有的、对位的集合有意义的成员函数。如果你不需要迭代器和动态地改变大小,那么你可能会发现bitset很适合你的需要。
现在我来介绍那个失败了的雄心勃勃的试验,正是这个试验把并非容器的vector<bool>留在了STL中。先前我曾经提到,代理对象在C++软件开发中经常会很有用。C++标准委员会的人很清楚这一点,所以他们决定开发vector<bool>,以演示STL如何支持“通过代理来存取其元素的容器”。他们说,C++标准中有了这个例子,于是,人们在实现自己的基于代理的容器时就有了一个现成的参考。
提示
然而,他们却发现,要创建一个基于代理的容器,同时又要求它满足STL容器的所有要求是不可能的。由于种种原因,他们失败了的尝试被遗留在标准中。人们可能会猜测为什么vector<bool>留了下来,但实际上,这无关紧要。重要的是:vector<bool>不完全满足STL容器的要求;你最好不要使用它;你可以用deque<bool>和bitset来替代它,这两个数据结构几乎能做vector<bool>所能做的一切事情。
第3章 关联容器
就像电影《绿野仙踪》中的多色马一样,关联容器是一些不同颜色的动物。没错,它们和序列容器有很多相同的特性,但在很多方面也有本质的不同。比如,它们会自动排序;它们按照等价(equivalence)而不是相等(equality)的标准来对待自己的内容;set和map不允许有重复的项目;map和multimap通常忽略它们所包含的每个对象中的一半。没错,关联容器是容器,但如果你能允许我把vector和string比作堪萨斯州的话,那么我们肯定不会还在堪萨斯州了。
第19条:理解相等(equality)和等价(equivalence)的区别。
在实际操作中,相等的概念是基于operator==的。如果表达式“x==y”返回真,则x和y的值相等,否则就不相等。这很直接明了,但是你脑子里应该记住,x和y有相等的值并不一定意味着它们的所有数据成员都有相等的值。比如,我们可能有一个Widget类,它在内部记录着自己最近一次被访问的时间:
class Widget {
public:
private:
TimeStamp lastAccessed;而我们可能有一个针对Widget的operator==,它忽略了这个域:
bool operator==(const Widget& lhs, const Widget& rhs) {
//忽略了lastAccessed域的代码
}在这种情况下,两个Widget即使有不同的lastAccessed域,它们也可以有相等的值。
等价关系是以“在已排序的区间中对象值的相对顺序”为基础的。如果你从每个标准关联容器(即set、multiset、map和multimap,排列顺序也是这些容器的一部分)的排列顺序来考虑等价关系,那么这将是非常有意义的。对于两个对象x和y,如果按照关联容器c的排列顺序,每个都不在另一个的前面,那么称这两个对象按照c的排列顺序有等价的值。这听起来很复杂,但其实不然。举例来说,考虑set<Widget>s。如果两个Widget w1和w2,在s的排列顺序中哪个也不在另一个的前面,那么,w1和w2对于s而言有等价的值。set<Widget>的默认比较函数是less<Widget>,而在默认情况下less<Widget>只是简单地调用了针对Widget的operator<,所以,如果下面的表达式结果为真,则w1和w2对于operator<有等价的值:
!(w1 < w2); //w1<w2 不为真
&& //而且
!(w2 < w1); //w2<w1 不为真这里的含义是:如果两个值中的任何一个(按照一定的排序准则)都不在另一个的前面,那么这两个值(按照这一准则)就是等价的。
注
在一般情形下,一个关联容器的比较函数并不是operator<,甚至也不是less,它是用户定义的判别式(predicate)。(要想了解有关判别式的更多信息,请参见第39条。)每个标准关联容器都通过key_comp成员函数使排序判别式可被外部使用,所以,如果下面的表达式为true,则按照关联容器c的排序准则,两个对象x和y有等价的值:
!c.key_comp()(x,y)&& !c.key_comp()(y, x) //在c的排列顺序中,x在y之前1不为真,y在x之前也不为真表达式!c.key_comp()(x,y)看起来很讨厌,但一旦你理解了c.key_comp返回一个函数(或者一个函数对象),它就不显得那么讨厌了。!c.key_comp()(x,y)仅仅是调用key_comp返回的函数(或函数对象),并以x和y作为传入参数。然后它把结果取反。只有当x按照c的排列顺序在y之前时,c.key_comp()(x,y)才返回真,所以,只有当x按照c的排列顺序不在y之前时,!c.key_comp()(x,y)才为真。
注
有了CIStringCompare,很容易就能建立一个不区分大小写的set<string>:
set<string, CiStringCompare> ciss; //ciss=“不区分大小写的字符串集”如果我们把字符串“Persephone”和“persephone”插入到该集合中,则只有第一个字符串会被插入,因为第二个和第一个等价:
ciss.insert("Persephone"); //一个新元素被插入到集合中
ciss.insert("persephone"); //没有新元素被插入到集合中如果我们用set的find成员函数来查找字符串“persephone”,则该查找会成功:
if (ciss.find("persephone") != ciss.end())...//该检查将成功但如果我们使用非成员的6nd算法,则查找将失败:
if (find(ciss.begin(), ciss.end(), "persephone") != ciss.end())...//该检查将失败这是因为“persephone”与“Persephone”等价(按照比较函数子CIStringCompare),但并不相等(因为string("persephone")!=string("Persephone"))。该例子从一个方面解释了为什么你应该遵循第44条中的建议,优先选用成员函数(像set::find)而不是与之对应的非成员函数(像find)。
标准关联容器总是保持排列顺序的,所以每个容器必须有一个比较函数(默认为less)来决定保持怎样的顺序。等价的定义正是通过该比较函数而确定的,因此,标准关联容器的使用者要为所使用的每个容器指定一个比较函数(用来决定如何排序)。如果该关联容器使用相等来决定两个对象是否有相同的值,那么每个关联容器除了用于排序的比较函数外,还需要另一个比较函数来决定两个值是否相等。(默认情况下,该比较函数应该是equal_to,但有趣的是,equal_to从来没有被用作STL的默认比较函数。当STL中需要相等判断时,一般的惯例是直接调用operator==。比如,非成员函数find算法就是这么做的。)
有趣的是,一旦你离开了排序的关联容器的领域,情况就发生了变化,相等与等价的问题可以被——也已经被——重新看待。对于非标准的(但使用很普遍的)基于散列表的关联容器,有两种常见的设计。一种是基于相等的,而另一种则是基于等价的。我鼓励你转过去读一读第25条,以便更多地了解这些容器和它们所采用的设计策略
提示
总之,使用单一的比较函数,并把等价关系作为判定两个元素是否“相同”的依据,使得标准关联容器避免了一大堆“若使用两个比较函数将带来的问题”。乍一看,它们的行为可能有些古怪(尤其是当你意识到成员的和非成员的find会返回不同的结果的时候),但从长远来看,这样做避免了在标准关联容器中混合使用相等和等价将会带来的混乱。
第20条:为包含指针的关联容器指定比较类型。
如果你想让string* 指针在集合中按字符串的值排序,那么你不能使用默认的比较函数子类(functor class)less<string* >。你必须自己编写比较函数子类,该类的对象以string* 指针为参数,并按照它们所指向的string的值进行排序。
这里的问题是,set模板的三个参数每个都是一个类型。不幸的是,stringPtrLess不是一个类型,它是一个函数。这就是为什么试图用stringPtrLess作为set的比较函数无法通过编译的原因。set不需要一个函数,它需要的是一个类型,并在内部用它创建一个函数。
哦,还有一件事情。本条款是关于包含指针的关联容器的,但它同样也适用于其他一些容器,这些容器中包含的对象与指针的行为相似,比如智能指针和迭代器。如果你有一个包含智能指针或迭代器的容器,那么你也要考虑为它指定一个比较类型。幸运的是,对指针的解决方案同样也适用于那些类似指针的对象。就像DereferenceLess适合作为包含T* 的关联容器的比较类型一样,对于容器中包含了指向T对象的迭代器或智能指针的情形,DereferenceLess也同样可用作比较类型。
第21条:总是让比较函数在等值情况下返回false。
很简单,结果是false。也就是说,该集合的结论是10A 和10B 不等价,从而不相同,因此,10B 将会被插入到容器中10A 的旁边。从技术角度来看,这会导致不确定的行为,但更普遍的后果是,会导致集合中有10的两份副本,这意味着它不再是一个集合!通过使用less_equal作为我们的比较类型,我们破坏了set容器!而且,任何一个比较函数,如果它对相等的值返回true,则都会导致同样的结果。相等的值按照定义却是不等价的。很酷,是不是?
为了避免跌入这个陷阱,你只要记住,比较函数的返回值表明的是按照该函数定义的排列顺序,一个值是否在另一个之前。相等的值从来不会有前后顺序关系,所以,对于相等的值,比较函数应当始终返回false。
提示
从技术上来说,用于对关联容器排序的比较函数必须为它们所比较的对象定义一个“严格的弱序化”(strict weak ordering)。(对于传递给像sort这类算法(见第31条)的比较函数也有同样的限制。)即,任何一个定义了“严格的弱序化”的函数必须对相同值的两个副本返回false。
第22条:切勿直接修改set或multiset中的键。
这是因为,对于一个map<K,V>或multimap<K,V>类型的对象,其中的元素类型是pair<const K,V>。因为键的类型是const K,所以它不能被修改。(喔,如果利用const_cast,你或许可以修改它,后面我们将会看到。不管你是否相信,有时你可能希望这样做。
但请注意,本条款的标题中并没有提到map或multimap。这是有原因的。正如上面的例子所演示的,直接修改键的值对map或multimap是行不通的(除非使用强制类型转换),但对set和multiset是可能的。对于set<T>或multiset<T>类型的对象,容器中元素的类型是T,而不是const T。因此,只要你愿意,你随时可以改变set或multiset中的元素,而无须任何强制类型转换。(实际上,事情并不是这么简单,但我们稍后再讨论这一点。没理由太着急。我们先爬行一段,然后再在碎玻璃上爬行。)
因为我们在这里所做的是修改雇员中与集合的排序方式无关的部分(雇员记录中不属于键的部分),所以这段代码不会破坏该集合。因此它是合法的。但使它合法就意味着set/multiset的元素不能为const。这解释了它们为什么不是const的原因。
因为set或multiset中的值不是const,所以,对这些值进行修改的代码可以通过编译。本条款的目的是提醒你,如果你改变了set或multiset中的元素,请记住,一定不要改变键部分(key part)——元素的这部分信息会影响容器的排序性。如果改变了这部分内容,那么你可能会破坏该容器,再使用该容器将导致不确定的结果,而错误的责任在于你。另一方面,这项限制只适用于被包含对象的键部分。对于被包含元素的其他部分,则完全是开放的;尽管修改吧!
因为标准的模棱两可,以及由此产生的不同理解,所以,试图修改set或multiset中元素的代码将是不可移植的。
注
啊哈,强制类型转换。我们已经看到,改变set或multiset中元素的非键部分是合理的,所以我觉得有必要向你演示一下如何做到这一点。也就是说,怎样正确地修改元素的非键部分,并且是可移植的做法。这并不难,但是需要一个常常被许多程序员所忽略的技巧:你必须首先强制转换到一个引用类型。作为一个例子,再来看看setTitle调用,我们已经知道在有些实现下它不能通过编译:
EmplDSet::iteratori=se.find(selectedlD);
if (i != se.end()) {
i->setTitle("Corporate Deity"); //有些STL实现将认为这一行不合法,因为*i为const
}为了使它能够编译和正确执行,我们必须把* i的常量性质(constness)转换掉。下面是正确的做法:
if (i != se.end()) {
const_cast<Employee&>(*i).setTitle("Corporate Deity"); //转换掉*i的const性质
}它将取得i所指的对象,并告诉编译器把类型转换的结果当作一个指向(非const的)Employee的引用,然后对该引用调用setTitle。我暂时不解释为什么这样做是可以的,而是先来解释为什么另一种方式不能像人们所期望的那样工作。
很多人写出这样的代码:
if (i != se.end()) {
static_cast<Employee>(*i).setTitle("Corporate Deity"); //把*i转换成Employee
}它与下面的方式是等价的:
if (i != se.end()) {
((Employee)(*i)).setTitle("Corporate Deity"); //同上。只是使用了C方式的类型转换
}这两种方式都能通过编译。因为它们是等价的,所以它们出错的原因也相同。在运行时,它们不会修改* i!在这两种情况下,类型转换的结果是一个临时的匿名对象,它是* i的一个副本,setTitle被作用在这个临时对象上,而不是* i上!* i没有改变,因为setTitle从来没有被作用于该对象,相反,它是在该对象的副本上被调用的。这两种语法形式都等价于:
if (i != se.end()){
Employee tempCopy(*i); //把*i复制到tempCopy
tempCopy.setTitle("Corporate Deity"); //修改tempCopy
}现在,强制转换到引用的重要性应该很清楚了。通过强制转换到引用类型,我们避免了创建新的对象。这样,类型转换的结果将会指向已有的对象,即i所指的那个对象。当setTitle被作用在该引用所指的对象上时,我们是在对* i调用setTitle,而这正是我们所期望的。
我刚才所说的对于set和multiset没有任何问题,但对于map和multimap,情况就有些复杂了。前面提到过,map<K,V>或multimap<K,V>包含的是pair<const K,V>类型的元素。这里的const意味着pair的第一个部分被定义成const,而这又意味着如果试图把它的const属性强制转换掉,则结果将可能会改变键部分。理论上,一个STL实现可以把这样的值写在一个只读的内存区域中(比如一个虚拟内存页面,一旦被写入后,将由一个系统调用进行写保护),这时若试图修改它,则最好的结果将是没有效果。我从来没有听说过有这样的STL实现,但如果你坚持要遵从C++标准所制定的规则,那就永远都不要试图修改在map或multimap中作为键的对象。
你肯定已经听说过强制类型转换是危险的,我希望本书能使这一点更加清楚。我也相信,只要你能避免使用它,你就不应该使用。执行一次强制类型转换就意味着临时关掉了类型系统的安全性,而我们刚才讨论过的隐患指出了当你放弃安全网的时候将会发生什么事情。
注
大多数强制类型转换都可以避免,包括我们刚刚考虑过的那个转换。如果你想以一种总是可行而且安全的方式来修改set、multiset、map和multimap中的元素,则可以分5个简单步骤来进行:
找到你想修改的容器的元素。如果你不能肯定最好的做法,第45条介绍了如何执行一次恰当的搜索来找到特定的元素。
为将要被修改的元素做一份副本。在map或multimap的情况下,请记住,不要把该副本的第一个部分声明为const。毕竟,你想要改变它。
修改该副本,使它具有你期望它在容器中的值。
把该元素从容器中删除,通常是通过调用erase来进行的(见第9条)。
把新的值插入到容器中。如果按照容器的排列顺序,新元素的位置可能与被删除元素的位置相同或紧邻,则使用“提示”(hint)形式的insert,以便把插入的效率从对数时间提高到常数时间。把你从第1步得来的迭代器作为提示信息。
下面是同样的Employee例子,这次是用安全的、可移植的方式来编写的:
EmplDSet se; //如前,se是按照ID号排序的雇员集合//如前,selectedID是存储有特定
Employee selectedlD; //ID号的Employee变量
EmplDSet::iterator i = se.find(selectedlD); //第1步:找到待修改的元素
if (i != se.end()) {
Employee e(*i); //第2步:复制该元素
e.setTitle("Corporate Deity"); //第3步:修改副本//第4步:删除该元素:
se.erase(i++); //递增迭代器以保持它的有效性(见第9条1/第5步:插入新元素:提示它的位置
se.insert(i, e); //和原来的相同
}提示
你要原谅我这么做,但关键是要记住,对set和multiset,如果你直接对容器中的元素做了修改,那么你要保证该容器仍然是排序的。
第23条:考虑用排序的vector替代关联容器。
标准关联容器通常被实现为平衡的二叉查找树。二叉查找树这种数据结构对插入、删除和查找的混合操作做了优化,也就是说,它所适合的那些应用程序先做一些插入操作,然后做查找,然后可能又插入一些元素,或许接着删掉一些,随后又做一些查找,然后是更多的插入和删除,更多的查找,等等。这一系列事件的主要特征是插入、删除和查找混在一起。总的说来,没办法预测出针对这棵树的下一个操作是什么。
先考虑大小的问题。假定我们需要一个容器来存储Widget对象,因为查找速度对我们很重要,所以我们考虑使用一个Widget的关联容器或一个排序的vector<Widget>。如果选择了关联容器,则我们几乎肯定在使用平衡二叉树。这样的树是由树节点构成的,每个节点不仅包含了一个Widget,而且还包含了几个指针:一个指针指向该节点的左儿子,一个指针指向该节点的右儿子,(通常)还有一个指针指向它的父节点。这意味着在一个关联容器中存储一个Widget所伴随的空间开销至少是3个指针。
相反,如果我们把Widget存储在vector中,则不会有任何额外开销;我们只是简单地存储一个Widget。当然,vector本身也有开销,在vector的末尾可能会有空闲的(预留的)空间(见第14条),但平均到每个vector,这些开销通常是微不足道的(通常是3个机器字,即3个指针或者2个指针加1个int),而且如果有必要,结尾的空闲空间可以用“swap技巧”去除(见第17条)。即便多余的空间没有被去除掉,它对下面的分析也没有影响,因为在做查找时这块内存根本就不会被引用到。
假定我们的数据结构足够大,它们被分割后将跨越多个内存页面,但vector将比关联容器需要更少的页面。这是因为vector不需要针对每个Widget付出额外的开销,而关联容器针对每个Widget需要3个指针。为了看清楚为什么这很重要,假定在你所使用的系统中,Widget的大小是12个字节,指针的大小是4字节,而一个内存页面可以容纳4096(4K)个字节。忽略对每个容器的开销,如果使用vector,则你在一个页面上可以存储341个Widget,而如果使用关联容器,则你最多只能存储170个。这样,跟使用vector相比,使用关联容器占用了大约两倍的内存。如果你的操作系统使用了虚拟内存,则很容易看出这将会导致更多的页面错误,从而当数据量很大的时候,系统会显著变慢。
提示
总结:在排序的vector中存储数据可能比在标准关联容器中存储同样的数据要耗费更少的内存,而考虑到页面错误的因素,通过二分搜索法来查找一个排序的vector可能比查找一个标准关联容器要更快一些。
当然,对于排序的vector,最不利的地方在于它必须保持有序!当一个新的元素被插入时,新元素之后的所有元素都必须向后移动一个元素的位置。听起来这很费事,实际上也确实如此,尤其是当vector必须重新分配自己的内存时(见第14条),因为这时通常需要复制vector中的所有元素。与此类似,如果一个元素被从vector中删除了,则在它之后的所有元素也都要向前移动。插入和删除操作对于vector来说是昂贵的,但对于关联容器却是廉价的。这就是为什么只有当你知道“对数据结构的使用方式是:查找操作几乎从不跟插入和删除操作混在一起”时,再考虑使用排序的vector而不是关联容器才是合理的。
为了用vector来模仿map或multimap,你必须要省去const,因为当你对这个vector进行排序时,它的元素的值将通过赋值操作被移动,这意味着pair的两个部分都必须是可以被赋值的。所以,当使用vector来模仿map<K,V>时,存储在vector中的数据必须是pair<K,V>,而不是pair<const K,V>。
第24条:当效率至关重要时,请在mapinsert之间谨慎做出选择。
map的operator[]函数与众不同。它与vector、deque和string的operator[]函数无关,与用于数组的内置operator[]也没有关系。相反,map::operator[]的设计目的是为了提供“添加和更新”(add or update)的功能。也就是说,对于map<K, V> m;,表达式 m[k]= v; 检查键k是否已经在map中了。如果没有,它就被加入,并以v作为相应的值。如果k已经在映射表中了,则与之关联的值被更新为v。
现在应该明白为什么这种方式会降低性能了。我们先默认构造了一个Widget,然后立刻赋给它新的值。如果“直接使用我们所需要的值构造一个Widget”比“先默认构造一个Widget再赋值”效率更高,那么,我们最好把对operator[]的使用(包括与之相伴的构造和赋值)换成对insert的直接调用:m.insert(IntWidgetMap::value type(1, 1.50)); 这里的最终效果和前面的代码相同,只是它通常会节省3个函数调用:一个用于创建默认构造的临时Widget对象,一个用于析构该临时对象,另一个是调用Widget的赋值操作符。这些函数调用的代价越高,使用mapoperator[]节省的开销就越大。
当我们做更新操作时,即,当一个等价的键(见第19条)已经在映射表中时,形势恰好反过来了。为了看清楚为什么会这样,请看一下做更新操作时我们的选择:
m[k] = v; //使用operator[]把k的值更新为v
m.insert(IntWidgetMap::value type(k, v)).first->second = v; //使用insert把k的值更新为V仅仅从语法形式本身来考虑,或许已经会促使你选择operator[]了,但现在我们要讲的是效率问题,所以我们将忽略这个因素。
insert调用需要一个IntWidgetMap::value_type类型的参数(即pair<int,Widget>),所以当我们调用insert时,我们必须构造和析构一个该类型的对象。这要付出一个pair构造函数和一个pair析构函数的代价。而这又会导致对Widget的构造和析构动作,因为pair<int,Widget>本身又包含了一个Widget对象。而operator[]不使用pair对象,所以它不会构造和析构任何pair或Widget。
对效率的考虑使我们得出结论:当向映射表中添加元素时,要优先选用insert,而不是operator[];而从效率和美学的观点考虑,结论是:当更新已经在映射表中的元素的值时,要优先选择operator[]。
提示
当效率至关重要时,你应该在mapinsert之间仔细做出选择。如果要更新一个已有的映射表元素,则应该优先选择operator[];但如果要添加一个新的元素,那么最好还是选择insert
第25条:熟悉非标准的散列容器。
作为这些实现的使用者,你实际上可能会关心的是,SGI的实现把表的元素放在一个单向链表中,而Dinkumware的实现则使用了双向链表。这一区别值得注意,因为它影响到两个实现的迭代器类型。SGI的散列容器提供了前向迭代器(forward iterator),所以你失去了做逆向遍历的能力;在SGI的散列表实现中没有rbegin和rend成员函数。Dinkumware的散列容器的迭代器是双向的,所以它们同时提供了前向和逆向的遍历功能。从内存使用的角度来说,SGI的设计比Dinkumware的设计要节省一些。
提示
哪种设计对你的应用最适合呢?我不可能知道,只有你才能决定。本条款没有试图给出足够的信息能让你得出适当的结论。相反,本条款的目的是为了让大家明白,尽管STL本身没有散列容器,但是与STL兼容的散列容器(只是其接口、能力和行为各有不同)却不难得到。对于SGI和STLport的实现,你甚至可以免费获得,因为它们提供免费下载。
第4章 迭代器
本章旨在寻求上述问题的答案,并且将介绍一种在实践中没有得到足够关注的迭代器类型:istreambuf iterator。如果你喜欢使用STL,却对使用istream_iterator读取字符流的性能不很满意,那么istreambuf_iterator正是你所需要的工具。
第26条:iterator优先于const_iterator、reverse_iterator以及const_reverse_iterator。
注
让我们来看两点。首先看一下vector<T>容器中insert和erase函数的原型:
iterator insert(iterator position, const T& x);
iterator erase(iterator position);
iterator erase(iterator rangeBegin, iterator rangeEnd);每个标准容器都提供了类似的函数,只不过对于不同的容器类型,返回值有所不同。需要注意的是:这些函数仅接受iterator类型的参数,而不是const_iterator、reverse_iterator或者const_reverse_iterator。总是iterator!虽然容器类支持4种不同的迭代器类型,但其中有一种迭代器有着特殊的地位。这就是iterator。所以,iterator与其他的迭代器有所不同。
从图中还可以看出,我们没有办法从const_iterator转换得到iterator,也无法从const_reverse_iterator得到reverse_iterator。这一点非常重要,因为这意味着,如果你得到了一个const_iterator或者const_reverse_iterator,你就会发现很难将这些迭代器与容器的某些成员函数一起使用。这些成员函数要求iterator作为参数,却无法从常量类型的迭代器中直接得到iterator。如果你需要利用迭代器来指定插入或者删除元素的位置,则常量类型的迭代器往往是没有用处的。
注
有些版本的insert和erase函数要求使用iterator。如果你需要调用这些函数,那你就必须使用iterator。const和reverse型的迭代器不能满足这些函数的要求。
要想隐式地将一个const_iterator转换成iterator是不可能的,第27条中讨论的将const_iterator转换成iterator的技术并不普遍适用,而且效率也不能保证。
从reverse_iterator转换而来的iterator在使用之前可能需要相应的调整,第28条讨论了为什么需要调整以及何时进行调整。
注
对于设计良好的STL实现而言,情况确实如此。但对于其他一些实现,这段代码甚至无法通过编译。原因在于,这些STL实现将const_iterator的等于操作符(operator==)作为一个成员函数而不是一个非成员函数。而问题的解决办法却非常有意思:只要交换两个iterator的位置,就万事大吉了:
if (ci == i) //当上面的比较不能编译的时候,这是解决方法不仅在进行相等比较的时候会发生这样的问题,只要在同一个表达式中混用iterator和const_iterator(或者reverse_iterator和const_reverse_iterator),这样的问题就会出现。例如,当试图在两个随机访问迭代器之间进行减法操作时:
if(i-ci >= 3) //如果i与ci之间至少有3个元素如果迭代器的类型不同,你(完全正确)的代码也可能会被(无理地)拒绝。你期望的解决办法是交换i和ci的位置,但这一次,你要考虑的就不仅仅是用ci-i来代替i-ci了:
if( ci + 3 <=i) //当上面的if语句不能编译的时候,这是解决方法而且,这样的变换并不总是正确的,ci+3也许不是一个有效的迭代器,它可能会超出容器的有效范围。而变换前的表达式中则不存在这样的问题。
提示
避免这种问题的最简单办法是减少混用不同类型的迭代器的机会,尽量使用iterator来代替const_iterator。从const正确性的角度(这确实是一个很值得考虑的角度)来看,仅仅为了避免一些可能存在的STL实现缺陷(而且,这些缺陷都有较为直接的解决途径)而放弃const_iterator显得有欠公允。但考虑到在容器类的某些成员函数中指定使用iterator的现状,得出iterator较之const_iterator更为实用的结论也就不足为奇了。更何况,从实践的角度来看,并不总是值得卷入const_iterator的麻烦中。
第27条:使用distance和advance将容器的const_iterator转换成iterator。
注
如果你得到了一个const_iterator并且可以访问它所在的容器,那么这里有一条安全的、可移植的途径能得到对应的iterator,而且用不着涉及类型系统的强制转换。下面是这种方案的本质,不过,这段代码还需要稍做修改才能通过编译。
typedef deque<int> IntDeque; //同前
typedef IntDeque::iterator lter;
typedef IntDeque::const_iterator Constlter;
IntDeque d;
Constlter ci;
... //使ci指向d
lter i(d.begin()); //使i指向d的起始位置
advance(i, distance(i, ci)); //移动i,使它指向ci所指的位置//(下面说明了为什么需要修改才能编译)这种方法看上去非常简单和直接,也很令人惊奇。为了得到一个与const_iterator指向同一位置的iterator,首先创建一个新的iterator,将它指向容器的起始位置,然后取得const_iterator距离容器起始位置的偏移量,并将iterator向前移动相同的偏移量即可。这项任务是通过<iterator>中声明的两个函数模板来实现的:distance用以取得两个迭代器(它们指向同一个容器)之间的距离;advance则用于将一个迭代器移动指定的距离。如果i和ci指向同一个容器,则表达式advance(i,distance(i,ci))会使i和ci指向容器中相同的位置。
注
要想让distance调用顺利地通过编译,你需要排除这里的二义性。最简单的办法是显式地指明distance所使用的类型参数,从而避免让编译器来推断该类型参数。
advance(i, distance<Constlter>(i, ci)) //将i和ci都当作const iterator,
//计算出它们之间的距离,然后将i移动//这段距离现在我们知道了如何使用advance和distance来从const_iterator获得iterator。但另一个值得认真考虑的问题是,这项技术的效率如何?答案很简单,它的效率取决于你所使用的迭代器。对于随机访问的迭代器(如vector、string和deque产生的迭代器)而言,它是一个常数时间的操作;对于双向迭代器(所有其他标准容器的迭代器,以及某些散列容器实现(见第25条)的迭代器)而言,它是一个线性时间的操作。
提示
这种从const_iterator获得iterator的转换技术可能需要线性时间的代价,并且需要访问const_iterator所属的容器,否则可能就无法完成,所以,你或许应该重新审视你的设计:是否真的需要从const_iterator到iterator的转换呢?实际上,这样的考虑也恰好激发了第26条的建议:在使用容器的时候,尽量用iterator来代替const或reverse型的迭代器。
第28条:正确理解由reverse_iterator的base()成员函数所产生的iterator的用法。
第26条指出了容器类的有些成员函数仅接受iterator作为迭代器参数。所以,对于上面的例子,如果你希望在ri指定的位置上插入一个新的元素,那么你就不能直接这样做,因为insert函数不接受reverse_iterator作为参数。如果你要删除ri所指的元素,则也存在同样的问题。erase成员函数也拒绝接受reverse_iterator,但可以接受iterator参数。为了执行插入或删除操作,你必须首先通过base成员函数将reverse_iterator转换成iterator,然后用iterator来完成插入或删除。
如果要在一个reverse_iterator ri指定的位置上插入新元素,则只需在ri.base()位置处插入元素即可。对于插入操作而言,ri和ri.base()是等价的,ri.base()是真正与ri对应的iterator。
如果要在一个reverse_iterator ri指定的位置上删除一个元素,则需要在ri.base()前面的位置上执行删除操作。对于删除操作而言,ri和ri.base()是不等价的,ri.base()不是与ri对应的iterator。
注
我们还是有必要来看一看执行这样一个删除操作的实际代码,其中暗藏着惊奇之处:
vector<int> v;
... //同上,插入1到5
vector<int>::reverse iterator ri = find(v.rbegin(), v.rend(), 3); //同上,使ri指向 3
v.erase(--ri.base()); //试图删除ri.base()前面位置上的元素;对于vector,往往编译通不过这段代码并不存在设计问题,表达式--ri.base()确实指出了我们希望删除的元素。而且,对于除了vector和string之外的所有标准容器,这段代码都能够正常工作。对于vector和string,这段代码或许也能工作,但对于vector和string的许多实现,它无法通过编译。这是因为在这样的实现中,iterator(和const_iterator)是以内置指针的方式来实现的,所以,ri.base()的结果是一个指针。
C和C++都规定了从函数返回的指针不应该被修改,所以,如果在你的STL平台上string和vector的iterator是指针的话,那么,类似--ri.base()这样的表达式就无法通过编译。因此,出于通用性和可移植性的考虑,要想在一个reverse_iterator指定的位置上删除一个元素,你应该避免直接修改base()的返回值。这没有问题。既然不能对base()的结果做递减操作,那么只要先递增reverse_iterator,然后再调用base()函数即可!
... //同上
v.erase((++ri).base()); //删除ri所指的元素;这下编译没问题了!因为这种方法对于所有的标准容器都是适用的,所以,当需要删除一个由reverse_iterator指定的元素时,应该首选这种技术。
提示
由此可见,通过base()函数可以得到一个与reverse_iterator“相对应的”iterator的说法并不准确。对于插入操作,这种对应关系确实存在;但是对于删除操作,情况却并非如此简单。当你将一个reverse_iterator转换成iterator的时候,很重要的一点是,你必须很清楚你将要对该iterator执行什么样的操作,因为只有在此基础上,你才能够确定这个iterator是不是你所需要的iterator。
第29条:对于逐个字符的输入请考虑使用istreambuf_iterator。
你应该会很快意识到这段代码并没有把文件中的空白字符复制到string对象中。因为istream_iterator使用operator>>函数来完成实际的读操作,而默认情况下operator>>函数会跳过空白字符。
请注意,这一次我们用不着清除输入流的skipws标志,因为istreambuf_iterator不会跳过任何字符,它只是简单地取回流缓冲区中的下一个字符,而不管它们是什么字符。
与istream_iterator相比,使用istreambuf_iterator的方案要快得多——我执行的一个简单测试表明,速度提高了近40%,当然,不同的STL实现其速度提高也会有所不同。而且,随着时间的推移,这种速度的提升可能会更加明显。由于istreambuf_iterator存在于STL中一个很少被访问的角落里,所以,大多数的STL实现者并没有花费更多的时间对它进行优化。例如,在我所使用的一个STL实现中,对于一次基本的测试,使用istreambuf_iterator仅仅比使用istream_iterator快5%左右。很显然,对于这样的实现,istreambuf_iterator的性能仍然有很大的提升空间。
提示
如果你需要从一个输入流中逐个读取字符,那么就不必使用格式化输入;如果你关心的是读取流的时间开销,那么使用istreambuf_iterator取代istream_iterator只是多输入了3个字符,却可以获得明显的性能改善。对于非格式化的逐个字符输入过程,你总是应该考虑使用istreambuf_iterator。
同样地,对于非格式化的逐个字符输出过程,你也应该考虑使用ostreambuf_iterator。它可以避免因使用ostream_iterator而带来的额外负担(但同时也损失了格式化输出的灵活性),从而具有更为优越的性能。
第5章 算法
第30条:确保目标区间足够大。
在这个例子中,transform的任务是,对values的每个元素调用transmogrify,并且将结果写到从results.end()开始的目标区间中。与其他使用目标区间的算法类似,transform通过赋值操作将结果写到目标区间中。于是,transform首先以values[0]为参数调用transmogrify,并将结果赋给* result.end()。然后,再以values[1]为参数调用transmogrify,并将结果赋给* (results.end()+1)。这可能会引起灾难性的后果!因为在* results.end()中并没有对象,* (results.end()+1)就更没有对象了。这种transform调用是错误的,因为它导致了对无效对象的赋值操作。(第50条将会解释调试版本的STL实现是如何在运行时检测到这种问题的。)
提示
本条款讲述了同一个问题的各种变化形式,需要牢记的是:无论何时,如果所使用的算法需要指定一个目标区间,那么必须确保目标区间足够大,或者确保它会随着算法的运行而增大。要在算法执行过程中增大目标区间,请使用插入型迭代器,比如ostream_iterator,或者由back_inserter、front_inserter和inserter返回的迭代器。这些都是你需要记住的。
第31条:了解各种与排序有关的选择。
sort、stable_sort、partial_sort和nth_element算法都要求随机访问迭代器,所以这些算法只能被应用于vector、string、deque和数组。对标准关联容器中的元素进行排序并没有实际意义,因为这样的容器总是使用比较函数来维护内部元素的有序性。list是唯一需要排序却无法使用这些排序算法的容器,为此,list特别提供了sort成员函数。(有趣的是,listiterator的容器,再对该容器执行相应的算法,然后通过其中的迭代器访问list的元素。第三种方法是利用一个包含迭代器的有序容器中的信息,通过反复地调用splice成员函数,将list中的元素调整到期望的目标位置。可以看到,你会有很多种选择。
总结一下所有这些排序选择
如果需要对vector、string、deque或者数组中的元素执行一次完全排序,那么可以使用sort或者stable_sort。
如果有一个vector、string、deque或者数组,并且只需要对等价性最前面的n个元素进行排序,那么可以使用partial_sort。
如果有一个vector、string、deque或者数组,并且需要找到第n个位置上的元素,或者,需要找到等价性最前面的n个元素但又不必对这n个元素进行排序,那么,nth_element正是你所需要的函数。
如果需要将一个标准序列容器中的元素按照是否满足某个特定的条件区分开来,那么,partition和stable_partition可能正是你所需要的。
如果你的数据在一个list中,那么你仍然可以直接调用partition和stable_partition算法;你可以用list::sort来替代sort和stable_sort算法。但是,如果你需要获得partial_sort或nth_element算法的效果,那么,正如前面我所提到的那样,你可以有一些间接的途径来完成这项任务。
注
我们可以依照算法的时间、空间效率将本条款中讨论过的算法列出如下,其中消耗资源较少的算法排在前面
- partition
- stable_partition
- nth element
- partial_sort
- sort
- stable_sort
提示
我的建议是,对排序算法的选择应该更多地基于你所需要完成的功能,而不是算法的性能。如果你选择的算法恰好能完成你所需要的功能(例如,使用partition而不是sort),那么多数情况下,这不仅可以使你的代码更加清晰,而且也是用STL来完成相应功能的最有效途径。
第32条:如果确实需要删除元素,则需要在remove这一类算法之后调用erase。
简而言之,remove移动了区间中的元素,其结果是,“不用被删除”的元素移到了区间的前部(保持原来的相对顺序)。它返回的一个迭代器指向最后一个“不用被删除”的元素之后的元素。这个返回值相当于该区间“新的逻辑结尾”。
把remove返回的迭代器作为区间形式的erase的第一个实参是很常见的,这是个习惯用法。事实上,remove和erase的配合是如此紧密,以致它们被合并起来融入到了list的remove成员函数中。这是STL中唯一一个名为remove并且确实删除了容器中元素的函数。坦率地说,调用这个remove函数其实是STL中一个不一致的地方。在关联容器中类似的函数被称为erase。照理来说,list的remove也应该被称为erase。然而它并没有被命名为erase,所以我们只好习惯这种不一致。我们乐于其中的这个世界可能不是最好的,但这是我们所拥有的。(另一方面,在第44条中将会谈到,对于list,调用remove成员函数比使用erase-remove习惯用法更为高效。)
提示
remove和remove_if的相似性是很显然的,无须我多说了;但是unique也和remove行为相似。它也需要在没有任何容器信息的情况下,从容器中删除一些元素(相邻的、重复的值)。所以,如果你真想从容器中删除元素的话,就必须在调用unique之后再调用erase。unique与list的结合也与remove的情形类似。如同listunique也会真正删除元素(而且比使用erase-unique更为高效)。
第33条:对包含指针的容器使用remove这一类算法时要特别小心。
提示
无论你如何处理那些存放动态分配的指针的容器,你总是可以这样来进行:或者通过引用计数的智能指针,或者在调用remove类算法之前先手工删除指针并将它们置为空,或者用你自己发明的其他某项技术。本条款的指导原则是一致的:对包含指针的容器使用remove类算法时需要特别警惕。如果你不留意这条警告的话,其后果就是资源泄漏。
第34条:了解哪些算法要求使用排序的区间作为参数。
注
这里我先罗列出那些要求排序区间的STL算法: binary_search lower_bound upper_bound equal_range set_union set_intersection set_difference set_symmetric_difference merge inplace_merge includes
另外,下面的算法并不一定要求排序的区间,但通常情况下会与排序区间一起使用: unique unique_copy
提示
这11个算法之所以要求排序的区间,目的是为了提供更好的性能。只要确保提供给它们排序的区间,并保证这些算法所使用的比较函数与排序所使用的比较函数一致,你就可以有效地使用这些与查找、集合操作以及区间合并有关的算法,并且你会惊喜地发现,unique和unique_copy如愿地删除了所有重复的值。
第35条:通过mismatch或lexicographical_compare实现简单的忽略大小写的字符串比较。
提示
关于mismatch和lexicographical_compare已经讲得够多了。虽然我在本书中把焦点集中在可移植性上,但是,忽略大小写的字符串比较函数也普遍存在于标准C库的非标准扩展中,如果我不提及这一点的话,就显得有点不负责任了。这些忽略大小写的字符串比较函数往往具有像strcmp或者strcmpi这样的名字,而且它们在国际化支持方面也不会比本条款中的函数更好。如果你愿意牺牲一点移植性,并且你知道你的字符串中不会包含内嵌的空字符,而且你不考虑国际化支持,那么你可能会发现,实现一个忽略大小写的字符串比较函数最容易的方法根本就不需要使用STL。相反,你可以把两个string转化成const char* 指针(见第16条),然后调用strcmp或strcmpi。有人可能会把这认为是一种取巧,但是,strcmp/strcmpi通常是被优化过的,它们在长字符串的处理上一般要比通用算法mismatch和lexicographical_compare快得多。如果对你来说这很重要,那么,你也许并不在意用非标准的C函数来代替标准的STL算法。有时候,最有效使用STL的途径是认识到其他的途径更加有效。
第36条:理解copy_if算法的正确实现。
注
下面是copy_if的正确实现:
template<typename Inputlterator //copy if的一个正确实现
typename Outputlterator,
typename Predicate>
Outputlterator copy_if(Inputlterator begin,
Inputlterator end,
Outputlterator destBegin,
Predicate p)
{
while (begin != end) {
if (p(*begin)) *destBegin++ = *begin;
++begin;
}
return destBegin;
}提示
其实copy_if是很有用的,很多STL程序员都希望有这个算法。你可以把这个正确的copy_if放到你本地的STL相关的工具库中,然后在适当的地方使用这个算法。
第37条:使用accumulate或者for_each进行区间统计。
注
double sum= accumulate(ld.begin(), ld.end(), 0.0); //计算它们的和,初始值为0.0在这个例子中,请注意初始值被指定为0.0,而不是简单的0。这非常重要,因为0.0的类型是double,所以accumulate的内部使用一个double类型的变量来保存它所计算的总和。
double sum= accumulate(ld.begin(), ld.end(), 0); //计算它们的和,初始值为0那么因为这里的初始值为int 0,所以accumulate的内部将使用一个int变量来保存它所计算的总和。而且这个int值最终将成为accumulate的返回值,然后再被用来初始化变量sum。这段代码既能够通过编译,也可以正常运行,但是sum的值不正确。它的结果不是这些double值的真正总和,而是把每次加法的结果都转换成整数之后得到的总和。
这段代码能够工作,但是,因为我有时候会跟一些狂热分子(他们中很多人是标准委员会的)打交道,所以我练就了一种本领:能够预想出STL的实现中哪里会失败。无论如何,PointAverage和标准中26.4.1节的第二段内容有冲突。我想你也应该知道,那就是,传给accumulate的函数不允许有副作用。而修改numPoints、xSum、ySum的值会带来副作用,所以从技术上说,刚才给出的代码其结果是不可预测的。从实践来说,很难想象它不能工作。但在这里,有很多语言专家们不允许我这么做,所以我没有选择,只好搬出标准来了。
先忽略副作用的问题不谈,for_each和accumulate在两个方面有所不同。首先,名字accumulate暗示着这个算法将会计算出一个区间的统计信息。而for_each听起来就好像是对一个区间的每个元素做一个操作,当然,这也正是算法的主要应用。用for_each来统计一个区间是合法的,但是不如accumulate来得清晰。
其次,accumulate直接返回我们所要的统计结果,而for_each却返回一个函数对象,我们必须从这个函数对象中提取出我们所要的统计信息。在C++中,这意味着我们必须在函数子类中加入一个成员函数,以便获得我们想要的统计信息。
提示
从我个人的观点来看,我宁愿使用accumulate,因为我认为它很清楚地表达了所要做的事情,当然for_each也能工作,而且副作用的问题对于for_each来说,也没有accumulate那样严重。两个算法都能用于统计区间。你可以从中挑选最适合你的算法。
第6章 函数子、函数子类、函数及其他
第38条:遵循按值传递的原则来设计函数子类。
由于函数对象往往会按值传递和返回,所以,你必须确保你编写的函数对象在经过了传递之后还能正常工作。这意味着两件事:首先,你的函数对象必须尽可能地小,否则复制的开销会非常昂贵;其次,函数对象必须是单态的(不是多态的),也就是说,它们不得使用虚函数。这是因为,如果参数的类型是基类类型,而实参是派生类对象,那么在传递过程中会产生剥离问题(slicing problem):在对象复制过程中,派生部分可能会被去掉,而仅保留了基类部分。(关于剥离问题对STL使用的影响,可参阅第3条,那里另有一个示例。)
从STL的角度看,需要牢记在心的一点是,如果函数子类用到了这项技术,那么它必须以某种合理的方式来支持复制动作。如果你是上述BPFC类的作者,那么你必须确保BPFC的复制构造函数正确地处理了它所指向的BPFCImpl对象。也许最简单而合理的做法是使用引用计数,可以采用类似于Boost的shared_ptr这样的辅助类(有关shared_ptr请参阅第50条)。
提示
事实上,从本条款的意图来看,唯一需要谨慎处理的就是BPFC的复制构造函数,因为函数对象在STL中作为参数传递或者返回的时候总是按值方式被复制的。这意味着两件事情:第一,使它们小巧;第二,使它们成为单态的。
第39条:确保判别式是“纯函数”。
注
一个判别式(predicate)是一个返回值为bool类型(或者可以隐式地转换为bool类型)的函数。在STL中,判别式有着广泛的用途。标准关联容器的比较函数就是判别式;对于像find_if以及各种与排序有关的算法,判别式往往也被作为参数来传递。(关于与排序有关的算法,请参见第31条中的介绍。)
一个纯函数(pure function)是指返回值仅仅依赖于其参数的函数。例如,假设f是一个纯函数,x和y是两个对象,那么只有当x或者y的值发生变化的时候,f(x,y)的返回值才可能发生变化。
在C++中,纯函数所能访问的数据应该仅局限于参数以及常量(在函数生命期内不会被改变,自然地,这样的常量数据应该被声明为const)。如果一个纯函数需要访问那些可能会在两次调用之间发生变化的数据,那么用相同的参数在不同的时刻调用该函数就有可能会得到不同的结果,这将与纯函数的定义相矛盾。
上述两个概念应该已经明确了“确保判别式是‘纯函数’”的意义。但为了更清楚地交待个中缘由,我希望你能原谅我还要引入另外一个概念:
- 判别式类(predicate class)是一个函数子类,它的operator()函数是一个判别式,也就说是,它的operator()返回true或者false。正如你所料,STL中凡是能接受判别式的地方,就既可以接受一个真正的判别式,也可以接受一个判别式类的对象。
为了避免在这种语言实现细节上栽跟头,最简单的解决途径就是在判别式类中,将operator()函数声明为const。这样,如果你还是像刚才那样做的话,编译器不会让你改变任何一个数据成员。因为这种解决问题的方式是如此简单而又直观,以至于我差一点将本条款的标题确定为“确保将判别式类的operator()函数声明为const”。但是,这样做还远远不够。即使是const成员函数,它也可以访问mutable数据成员、非const的局部static对象、非const的类static对象、名字空间域中的非const对象,以及非const的全局对象。一个精心设计的判别式类应该保证其operator()函数完全独立于所有这些变量。所以,在判别式类中将operator()声明为const,这对于判别式的正确行为是必要的,但还不足以完全解决问题。一个行为正常的判别式的operator()肯定是const的,但是它还有更严格的要求。它还应是一个“纯函数”。
第40条:若一个类是函数子,则应使它可配接。
STL函数对象是C++函数的一种抽象和建模形式,而每个C++函数只有一组确定的参数类型和一个返回类型。所以,STL总是假设每个函数子类只有一个operator()成员函数,并且其参数和返回类型应该吻合unary_function或binary_function的模板参数(当然,必须遵循我们讨论过的关于引用和指针类型的规则)。这也就意味着,虽然只要创建一个包含两个operator()函数的结构,就可以把WidgetNameCompare和PtrWidgetNameCompare的功能合并到一个函数s子结构(functor struct)中,但最好不要这样做。如果这样做了,那么这样的函数子至多只有一种调用形式是可配接的(取决于binary_function接受的模板参数与哪个是一致的)。一个只有一半配接能力的函数子恐怕并不比完全不可配接的函数子强多少。
提示
但有时确实需要函数子类具有多种不同的调用形式(也就意味着放弃了其可配接能力),第7条、第20条、第23条和第25条中给出了这种函数子可能出现的一些场合。然而,这样的函数子类是例外,不是标准。配接能力是很重要的,每当你编写函数子类的时候,你都应该坚持让你的函数子类具有可配接能力。
第41条:理解ptr_fun、mem_fun和mem_fun_ref的来由。
但是理想与现实总还是有那么一点差距的。在调用#1的for_each函数中,我们用一个对象来调用一个非成员函数,所以我们使用了语法#1。在调用#2的for_each函数中,我们必须使用语法#2,因为我们面对的是一个对象和一个成员函数。在调用#3的for_each函数中,我们需要使用语法#3,因为我们在处理一个成员函数和一个对象指针。因此我们需要3个不同版本的for_each算法实现!这真的是我们的理想世界吗?
总的来说,mem_fun将语法#3调整为语法#1;当通过一个Widget* 指针来调用Widget::test的时候,语法#3是必需的;而for_each使用的是语法#1,所以mem_fun的这种调整是必要的。因此,像mem_fun_t这样的类被称为函数对象配接器(function object adapter)。你可能已经猜到了,mem_fun_ref函数完全与此类似,它将语法#2调整为语法#1,并产生一个类型为mem_fun_ref_t的配接器对象。
如果你对什么时候该使用ptr_fun,什么时候不该使用ptr_fun感到困惑,那么你可以在每次将一个函数传递给一个STL组件的时候总是使用它。STL不会在意的,而且这样做也不会带来运行时的性能损失。最糟糕的顶多是,在其他人阅读你的代码时,如果看到了不必要的ptr_fun可能会皱起眉头。所以,我可以这样认为,你是否选择这种做法完全取决于你对于皱眉现象的承受能力。另一种策略是,只有在迫不得已的时候才使用ptr_fun。如果你省略了那些必要的类型定义,编译器就会提醒你。然后你再回去把ptr_fun加上。
mem_fun和mem_fun_ref的情形则截然不同。每次在将一个成员函数传递给一个STL组件的时候,你就要使用它们。因为它们不仅仅引入了一些类型定义(可能是必要的,也可能不是必要的),而且它们还转换调用语法的形式来适应算法——它们将针对成员函数的调用语法转换为STL组件所使用的调用语法。如果你在传递成员函数指针的时候不使用它们,那么你的代码永远也无法通过编译。
提示
最后剩下的只是这些配接器名字的问题了,这是真正的STL历史产物。当针对这些配接器的需求第一次变得非常明显的时候,STL的工作人员正把注意力集中在指针容器上。(了解了第7条、第20条和第33条中指出的种种缺陷后,这也许比较令人惊奇。但请记住,指针容器支持多态,而对象容器却不支持多态。)他们需要一个针对成员函数的配接器,所以他们选择了mem_fun这个名字。后来,他们意识到还需要另外一个针对对象容器的配接器,所以它们只好使用名字mem_fun_ref了。这名字实在是不怎么雅致,但已经是既成事实了。你是不是也有这样的起名字经历呢?先为自己的组件起了一个名字,后来发现难以将这个名字进一步泛化了……
第42条:确保less<T>与operator<具有相同的语义。
operator<不仅仅是less的默认实现方式,它也是程序员期望less所做的事情。让less不调用operator<而去做别的事情,这会无端地违背程序员的意愿,这与“少带给人惊奇”的原则(the principle of least astonishment)完全背道而驰。这是很不好的,你应该尽量避免这样做。
提示
应该尽量避免修改less的行为,因为这样做很可能会误导其他的程序员。如果你使用了less,无论是显式地或是隐式地,你都需要确保它与operator<具有相同的意义。如果你希望以一种特殊的方式来排序对象,那么最好创建一个特殊的函数子类,它的名字不能是less。这样做其实是很简单的。
第7章 在程序中使用STL
第43条:算法调用优先于手写的循环。
注
对许多C++程序员来说,编写一个循环比调用一个算法更自然,阅读循环代码比弄懂mem_fun_ref的意义以及弄懂取Widget::redraw地址的用意更为轻松。然而本条款却告诉你,事实上调用算法通常是更好的选择,它往往优先于任何一个手写循环。为什么呢?有三个理由:
效率 。算法通常比程序员自己写的循环效率更高。
正确性 。自己写循环比使用算法更容易出错。
可维护性 。使用算法的代码通常比手写循环的代码更加简洁明了。
使用算法的关键是要熟知算法的名称。在STL中有70个算法名称,如果考虑到重载的情形,大约有100个不同的函数模板。每一个算法都完成了一项定义良好的任务,合理地讲,每一位专业C++程序员都应该知道(或者会查找)每一个算法所做的事情。因此,当一个程序员看到transform调用的时候,他应该意识到,某个函数将被应用到一个区间中的每一个对象上,而这些调用的结果将被写到某一个地方;当程序员看到replace_if调用的时候,他(或她)知道,区间中所有满足某个判别式条件的对象都将被修改;当程序员碰到partition调用的时候,就知道一个区间中的对象将会被移动,所有满足某个判别式条件的对象会被组织到一起(见第31条)。STL算法的名称提供了很多语义信息,这使它们比任何随机循环更为清晰易懂。
当你看到for、while或do的时候,你所知道的只不过是某一种循环将要出现。要想知道这个循环的用途,哪怕是最粗略的用途,你都必须检查具体的代码。但是,当你看到一个算法调用的时候,它的名称就会指示出它的用途。当然,如果你想知道它到底做了什么,你必须要检查那些传给算法的实参的含义,但这通常比看懂一个循环结构的意图要简单得多。
简而言之,算法的名称表明了它的功能,而for、while和do循环却不能。事实上,这对于标准C和C++库中的任何一个函数都是成立的。毫无疑问,如果愿意的话,你可以自己编写strlen、memset或者bsearch,但是你肯定不会自己写。为什么?因为:(1)已经有人实现了,你没有理由再去写一遍;(2)这些名字是标准的,每个人都知道它们的功能;(3)你觉得库的实现者比你知道更多的提高效率的技巧,所以你不愿意放弃一个有经验的库实现者可能提供的性能优化。就像你不会自己编写strlen等函数一样,使用手写循环而弃置已有的STL算法同样没有道理。
在算法调用与手写循环的斗争中,关于代码清晰度的底线最终取决于你要在循环中做什么事情。如果你要做的工作与一个算法所实现的功能很相近,那么用算法调用更好。但是如果你的循环很简单,而若使用算法来实现的话,却要求混合使用绑定器和配接器或者要求一个单独的函数子类,那么,可能使用手写的循环更好。最后,如果你在循环中要做的工作很多,而且又很复杂,则最好使用算法调用,因为又冗长又复杂的计算任务总是应该被放到单独的函数中。而一旦你把循环体移到了单独的函数中,那么你总是可以找到一种办法把这个函数传给一个算法(往往是for_each),这样得到的代码又直接、又清楚。
提示
如果你同意本条款中提出的“算法调用一般优先于手写循环”的建议,并且如果你也同意第5条中给出的“区间成员函数优先于循环调用单个元素的成员函数”的指导原则,那么自然就会得到这样一个有趣的结论:使用了STL的精巧的C++程序比不用STL的程序所包含的循环要少得多。这是一件好事。任何时候我们都应该尽量用较高层次的insert、find和for_each来替换较低层次的for、while和do,因为这样我们就提高了软件的抽象层次,从而使我们的软件更易于编写,更易于文档化,也更易于扩展和维护。
第44条:容器的成员函数优先于同名的算法。
有些STL容器提供了一些与算法同名的成员函数。比如,关联容器提供了count、find、lower_bound、upper_bound和equal_range,而list则提供了remove、remove_if、unique、sort、merge和reverse。大多数情况下,你应该使用这些成员函数,而不是相应的STL算法。这里有两个理由:第一,成员函数往往速度快;第二,成员函数通常与容器(特别是关联容器)结合得更加紧密,这是算法所不能比的。原因在于,算法和成员函数虽然有同样的名称,但是它们所做的事情往往不完全相同。
set容器的find成员函数以对数时间运行,所以,无论容器中是否存在727,set::find执行的比较次数都不会超过40次,而通常它只要求大约20次比较操作就可以了。相反,find算法以线性时间运行,所以,如果容器中不存在727的话,它必须执行1000000次比较操作。即使set中的确包含了727,find算法仍然需要平均500000次比较操作才能找到它。
在谈到find成员函数所要求的比较次数的时候,我必须非常谨慎,因为find成员函数所要求的比较次数与关联容器的具体实现有关,大多数STL中关联容器的底层实现都会选用红黑树结构(红黑树是平衡树的一种形式,它总是保持子树的节点数之比小于2,而非绝对平衡)。在这样的实现下,搜索一个包含1000000个元素值的集合所需要的最大比较次数为38,但是对于大多数的搜索,比较次数不会超过22。基于完全平衡树的实现永远不会超过21次比较,但在实践中,完全平衡树的总体性能略微逊色于红黑树的性能,这也正是为什么大多数STL实现采用了红黑树而不是平衡树的原因。
综上所述,对于标准的关联容器,选择成员函数而不选择对应的同名算法,这可以带来几方面的好处。第一,你可以获得对数时间的性能,而不是线性时间的性能。第二,你可以使用等价性来确定两个值是否“相同”,而等价性是关联容器的一个本质定义。第三,你在使用map和multimap的时候,将很自然地只考虑元素的键部分,而不是完整的(key,value)对。这三条应该足以说明关联容器成员函数的优势了。
现在我们转到list中那些具有同名STL算法的成员函数上。在这里,性能几乎成了全部的考虑因素。remove、remove_if、unique、sort、merge以及reverse这些算法无一例外地需要复制list容器中的对象,而专门为list容器量身定做的成员函数则无须任何对象副本,它们只是简单地维护好那些将list节点连接起来的指针。这些算法的时间复杂度并没有改变,但多数情况下维护指针的开销比复制对象要低得多,所以list的成员函数应该会提供更好的性能。
另外有一点很重要,你必须记住,list成员函数的行为不同于与其同名的算法的行为。正如第32条所述,如果真的要从一个容器中删除对象的话,你在调用了remove、remove_if或者unique算法之后,必须紧接着再调用erase;而list的remove、remove_if和unique成员函数则实实在在地删除了元素,所以你无须再调用erase了。
提示
因此,当需要在STL算法与容器的同名成员函数之间做出选择的时候,你应该优先考虑成员函数。几乎可以肯定地讲,成员函数的性能更为优越,而且它们更能够与容器的一贯行为保持一致。
第45条:正确区分count、find、binary_search、lower_bound、upper_bound和equal_range。
如果有一个未排序的区间,那么你的选择是count或find。由于它们回答的问题有些不同,所以值得更仔细地看一看这两个算法。count回答的问题是“区间中是否存在某个特定的值?如果存在的话,有多少个副本?”而find回答的问题则是“区间中有这样的值吗?如果有的话,它在哪里?”
从存在性测试的角度来看,count的习惯用法相对要容易编码一些。但同时,在搜索成功的情况下,它的效率要差一些,因为find找到第一个匹配结果后马上就返回了,而count必须到达区间的末尾,以便找到所有的匹配。对于大多数程序员来说,find在效率上的优势足以弥补它稍嫌复杂的用法。
对于已经排过序的区间,你还有其他的选择途径,而且你肯定会愿意使用那些方法。count和find以线性时间运行,而对于排序的区间,查找算法(binary_search、lower_bound、upper_bound和equal_range)以对数时间运行。
从未排序的区间到排序区间的转变也带来了另一种变化:前者利用相等性来决定两个值是否相同,而后者使用等价性作为判断依据。第19条讨论了相等和等价的问题,这里就不重复了。我想说明的是,count和find使用相等性进行搜索,而binary_search、lower_bound、upper_bound和equal_range则使用了等价性。
要想测试一个排序区间中是否存在某一个特定的值,你可以使用binary_search。与标准C/C++函数库中的bsearch不同的是,binary_search仅仅返回一个bool值:是否找到了特定的值。binary_search只回答“是否存在”的问题,它的答案不是“是”就是“否”。如果你需要更多的信息,那你就必须使用其他算法。
有一种更容易的办法:使用equal_range。equal_range返回一对迭代器:第一个迭代器等于lower_bound返回的迭代器,第二个迭代器等于upper_bound返回的迭代器(即指向该区间中与所查找的值等价的最后一个元素的下一个位置)。所以,equal_range返回的这一对迭代器标识了一个子区间,其中的值与你所查找的值等价。这个算法的名字很贴切吧,是不是?(当然,用equivalent_range可能更好,但是equal_range还是很不错的。)关于equal_range的返回值有两个需要注意的地方。第一,如果返回的两个迭代器相同,则说明查找所得的对象区间为空;即没有找到这样的值。这对于使用equal_range来回答“是否存在这样的值”是非常关键的。第二个需要注意的地方是,equal_range返回的迭代器之间的距离与这个区间中的对象数目是相等的,也就是原始区间中与被查找的值等价的对象数目。所以,对于排序区间而言,equal_range不仅完成了find的工作,同时也代替了count。
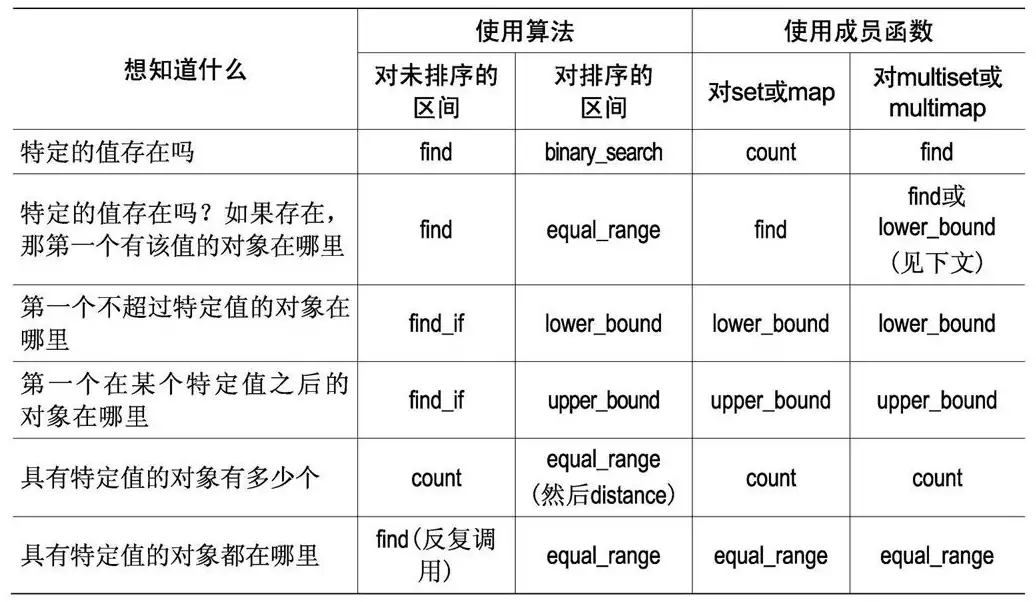
在count、find、binary_seach、lower_bound、upper_bound和equal_range中选择合适的算法或者成员函数是很容易的。选择能符合你的行为和性能要求的算法或者成员函数,同时当你调用所选择的算法或者成员函数的时候,所需要做的工作尽可能地最少。遵循以上建议(或者上面这个表格),你就应该不会有问题。
第46条:考虑使用函数对象而不是函数作为STL算法的参数。
对这种行为的解释也非常简单:函数内联。如果一个函数对象的operator()函数已经被声明为内联的(或者通过inline显式地声明,或者被定义在类定义的内部,即隐式内联),那么它的函数体将可以直接被编译器使用,而大多数编译器都乐于在被调算法的模板实例化过程中将该函数内联进去。在上面的例子中,函数greater<double>::operator()是一个内联函数,所以编译器在sort的实例化过程中将其内联展开。最终结果是,sort中不包含函数调用,编译器就可以对这段不包含函数调用的代码进行优化,而这种优化在正常情况下是很难获得的。
如果使用doubleGreater作为参数来调用sort算法,则情形有所不同。为了看清楚两种情形的不同之处,我们必须要清楚,在C/C++中并不能真正地将一个函数作为参数传递给另一个函数。如果我们试图将一个函数作为参数进行传递,则编译器会隐式地将它转换成一个指向该函数的指针,并将该指针传递过去。
函数指针参数抑制了内联机制,这个事实正好解释了一个长期以来C程序员们都不愿正视的现实:C++的sort算法就性能而言总是优于C的qsort。诚然,C++必须先实例化函数模板和类模板,然后再调用相应的operator()函数,相比之下,C只是进行了一次简单的函数调用。但是,C++的所有这些“额外负担”都在编译期间消化殆尽。在运行时,sort算法以内联方式调用它的比较函数(假设比较函数已经被声明为inline并且它的函数体在编译过程中是可用的),而qsort则通过一个指针来调用它的比较函数。所以最终的结果是,sort算法运行得更快一些。当我用一个包含一百万个double值的vector来进行测试的时候,sort比qsort快了670%!
提示
因此,以函数对象作为STL算法的参数,这种做法提供了包括效率在内的多种优势。从代码被编译器接受的程度而言,它们更加稳定可靠。当然,普通函数在C++中也是非常实用的,但是就有效使用STL而言,函数对象通常更加实用一些。
第47条:避免产生“直写型”(write-only)的代码
这就是为什么这种语句通常被称为“直写型”代码(write-only code)的原因。当你编写代码的时候,它看似非常直接和简捷,因为它是由某些基本想法(比如,erase-remove习惯用法加上在find中使用reverse_iterator的概念)自然而形成的。然而,阅读代码的人却很难将最终的语句还原成它所依据的思路,这就是“直写型代码”叫法的来历:虽然很容易编写,但是难以阅读和理解。
在软件工程领域中有这样一条真理:代码被阅读的次数远远大于它被编写的次数。一个等价的说法是:软件的维护过程通常比开发过程需要消耗更多的时间。如果无法正确地阅读和理解软件的含义,则自然也谈不上对软件的维护;一个无法被维护的软件恐怕也就不具备任何价值了。你使用STL越多,你就越是适应STL的工作方式,于是,你的代码中也就会有越多的嵌套函数调用和动态创建的函数对象。这本无可厚非,但需要时刻警觉的是,你今天编写的代码将来有一天可能会有人(也许正是你自己)来阅读。请为那一天的到来做好准备吧。
提示
是的,请使用STL,并且用好STL。还要有效地使用STL。但是,一定要避免“直写型”的代码。从长远来看,这样的代码绝对算不上有效。
第48条:总是包含(#include)正确的头文件。
注
为了帮助你记住什么时候需要包含哪些头文件,下面总结了每个与STL有关的标准头文件中所包含的内容:
几乎所有的标准STL容器都被声明在与之同名的头文件中,比如vector被声明在
<vector>中,list被声明在<list>中,等等。但是<set>和<map>是个例外,<set>中声明了set和multiset,<map>中声明了map和multimap。除了4个STL算法以外,其他所有的算法都被声明在
<algorithm>中,这4个算法是accumulate(参见第37条)、inner_product、adjacent_difference和partial_sum,它们被声明在头文件<numeric>中。特殊类型的迭代器,包括istream_iterator和istreambuf_iterator(见第29条),被声明在
<iterator>中。标准的函数子(比如
less<T>)和函数子配接器(比如not1、bind2nd)被声明在头文件<functional>中。
提示
任何时候如果你使用了某个头文件中的一个STL组件,那么你就一定要提供对应的#include指令,即使你正在使用的STL平台允许你省略#include指令,你也要将它们包含到你的代码中。当你需要将代码移植到其他平台上的时候,你的勤奋就会得到回报,移植的压力就会减轻。
第49条:学会分析与STL相关的编译器诊断信息。
提示
这里还有一些其他的技巧,也许对你分析与STL相关的诊断信息会有所帮助:
vector和string的迭代器通常就是指针,所以当错误地使用了iterator的时候,编译器的诊断信息中可能会引用到指针类型。例如,如果源代码中引用了
vector<double>::iterator,那么编译器的诊断信息中极有可能就会提及double* 指针。(如果你使用的是STLport的STL实现并且在调试模式下运行,则情形会有所不同,因为这时候vector和string的迭代器不是指针。关于STLport及其调试模式的相关信息,请参阅第50条。)如果诊断信息中提到了back_insert_iterator、front_insert_iterator或者insert_iterator,则几乎总是意味着你错误地调用了back_inserter、front_inserter或者inserter。(back_inserter返回一个back_insert_iterator类型的对象,front_inserter返回一个front_insert_iterator类型的对象,而inserter返回一个insert_iterator类型的对象。关于这些插入迭代器的用法,请参阅第30条。)如果你并没有直接调用这些函数,则一定是你所调用的某个函数直接或者间接地调用了这些函数。
类似地,如果诊断信息中提到了binder1st或者binder2nd,那么你可能是错误地使用了bind1st和bind2nd。(bind1st返回一个类型为binder1st的对象,而bind2nd则返回一个类型为binder2nd的对象。)
输出迭代器[如ostream_iterator、ostreambuf_iterator(见第29条),以及那些由back_inserter、front_inserter和inserter函数返回的迭代器]在赋值操作符内部完成其输出或者插入工作,所以,如果在使用这些迭代器的时候犯了错误,那么你所看到的错误消息中可能会提到与赋值操作符有关的内容。
如果你得到的错误消息来源于某一个STL算法的内部实现(例如,引起错误的源代码在
<algorithm>中),那也许是你在调用算法的时候使用了错误的类型。例如,你可能使用了不恰当的迭代器类型。如果你正在使用一个很常见的STL组件,比如vector、string或者for_each算法,但是从错误消息来看,编译器好像对此一无所知,那么可能是你没有包含相应的头文件。正如第48条中所述,在一个STL平台上能够顺利编译的代码,在移植到一个新的STL平台上时可能会出现这样的问题。
第50条:熟悉与STL相关的Web站点。
SGI STL 站点:http://www.sgi.com/tech/stl/。
STLport 站点:http://www.stlport.org。
Boost 站点:http://www.boost.org。
SGI STL站点
SGI的STL站点有充足的理由位居榜首。它为STL中的所有组件都提供了详尽的文档。对于大多数STL程序员而言,无论他们实际使用的是哪一个STL平台,这个站点都可以是他们的在线参考手册。(Matt Austern收集整理了这些文档,并以此为基础编写了Generic Programming and the STL 一书。)这个站点上的材料不仅覆盖了STL的组件,而且还有其他许多很有价值的信息。例如,本书中关于STL容器中线程安全性的讨论(见第12条)就是以SGI STL站点上的相关内容为基础的。
SGI站点还为STL程序员提供了另外的资源:一个可以免费下载的STL实现。这个STL实现仅仅被移植到了少数几个编译器上,但它却是另一个被广泛使用的STL版本STLport的基础,稍后我会介绍有关STLport的更多信息。同时,SGI的STL实现提供了许多非标准组件,这些组件使得STL程序设计更加强大、灵活和有趣。
SGI的库实现超出了STL的范畴。它的目标是开发一套完整的C++标准库实现,当然,其中不包括从C继承来的部分。(SGI假定你已经有了一个可由你自己支配的标准C库。)因此,另一个值得一提的是SGI的C++ iostream库实现,你同样可以从SGI站点免费下载获得。你可能已经猜到了,这个iostream库实现与SGI的STL实现紧密地集成在一起,并且它的性能也超过了许多C++编译器自带的iostream实现。
STLport站点
STLport最大的卖点在于,它提供了一个可以在超过20种编译器上使用的SGI STL(包括iostream等)改进版本。与SGI的库一样,STLport的库同样可以免费下载。如果你编写的代码必须在多个平台上工作,那么在所有的平台上统一使用STLport的STL实现,这样可以为你省去不少麻烦。
STLport对SGI STL的改进绝大多数是出于移植性的考虑,但STLport同时也提供了一种“调试模式”,通过这种模式,程序员可以检测到不正确使用STL的情形(特别是那些能够通过编译但是会导致未定义的运行时行为的STL用法),而据我所知,STLport是目前唯一一个提供了这种模式的STL实现。
Boost Web站点
1997年,当C++国际标准的制定工作行将结束的时候,一些C++的拥护者非常失望,因为他们所极力倡导的一些特性最终未能进入标准中。他们中的有些人也是C++标准委员会的成员,于是,这些人着手准备为下一轮的C++标准化过程提供一个增补的基础。Boost网站正是他们努力的结果,Boost站点的宗旨是“提供免费的、公开审视的C++库。重点在那些可与C++标准库很好地协同工作的可移植性库上”。他们这项工作的动机在于:
一个库越是具备“已成事实的实践基础”,那么它将来被建议增补进入C++标准的可能性就越大。将一个库提交到Boost.org正是建立起这种“已成事实的实践基础”的一条途径……
换言之,Boost网站提供了一种类似于“将绵羊从山羊中分离出来”的诊断机制,从而识别出那些具有潜在增补价值的C++库。这是一项非常有价值的服务,我们大家都应该向他们表示感谢。