
From Calibration to Refinement: Seeking Certainty via Probabilistic Evidence Propagation for Noisy-Label Person Re-Identification
News
The paper "CARE" has been accepted for publication in IEEE TMM 2026.
Comments: Accepted by IEEE TMM 2026
Subjects: Computer Vision and Pattern Recognition (cs.CV)
Cite as: arXiv:2602.23133 [cs.CV]
Introduction
Limitations of Existing Methods:
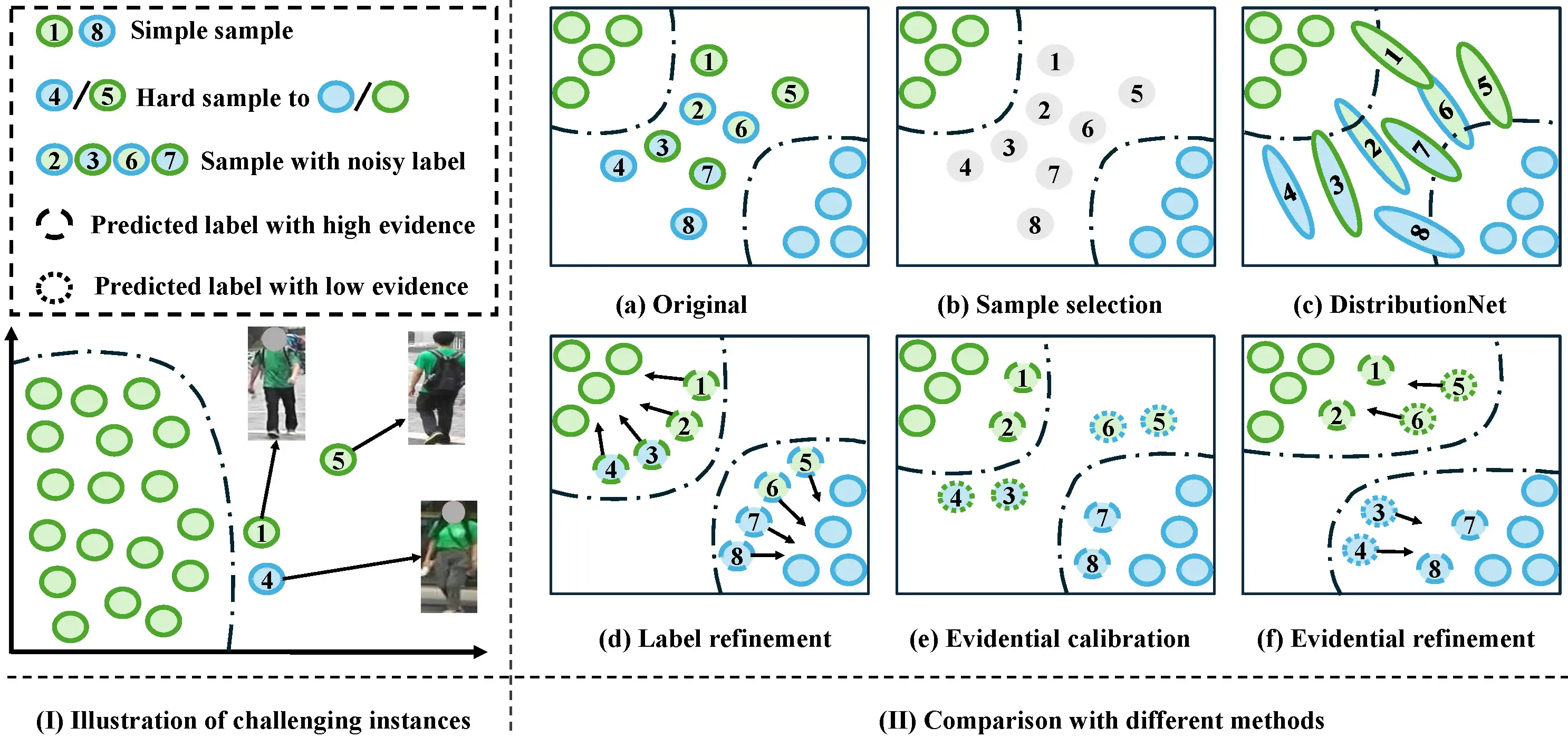
Left:
- Two challenging instances in feature space: Sample 4 (clean but close to another identity) and Sample 5 (hard sample with occlusion).
Right:
(a) Original samples with noisy labels;
(b) Sample selection methods filter out noisy but informative samples;
(c) DistributionNet uses uncertainty to model features, yet it still confuses similar features between clean and noisy labels;
(d) Label refinement methods based on softmax may produce the same probabilities for different samples, resulting in incorrectly refurbished labels;
CARE contains (e) evidential calibration and (f) evidential refinement:
(e) calibrates high evidential instances in the Calibration stage;
(f) refines low evidential instances in the Refinement stage.
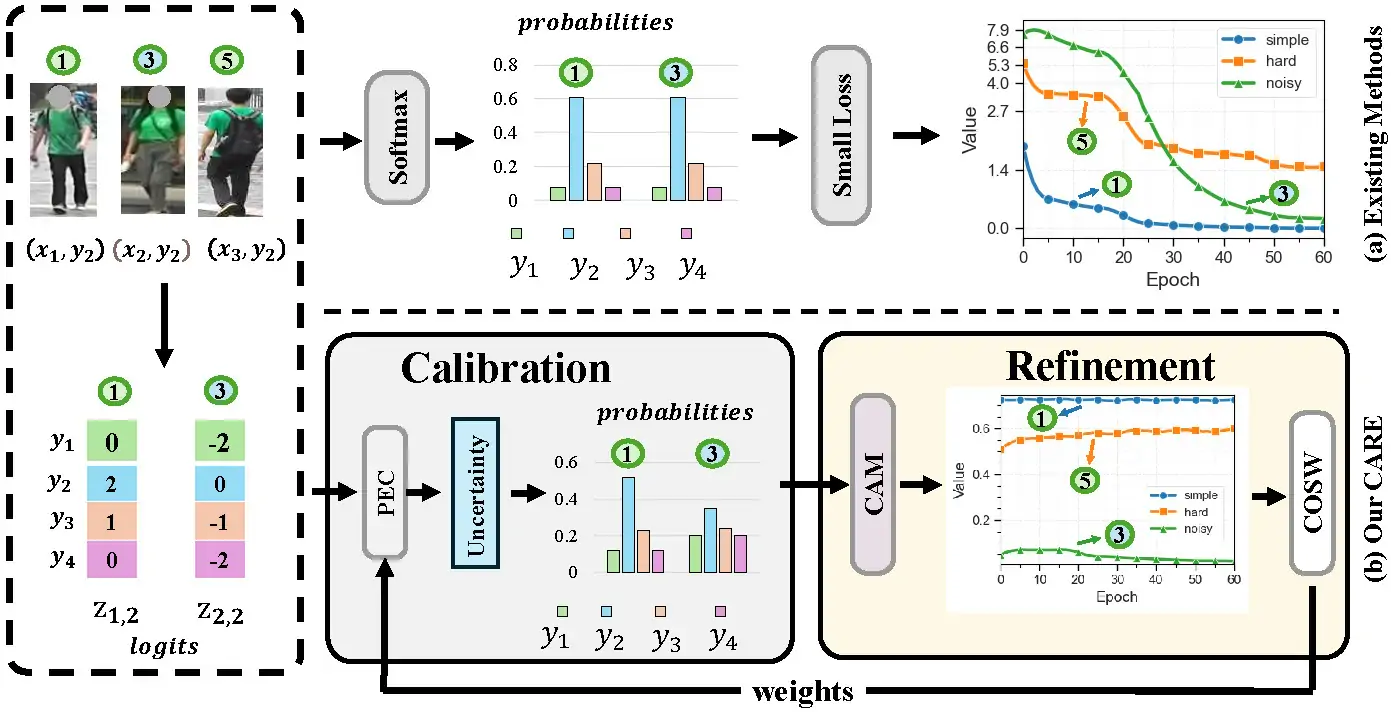
Motivation of Our CARE
Conventional Methods (Top Row):
Over-confidence: Traditional softmax-based scoring yields over-confident predictions even on corrupted labels.
Data Loss: Small-loss selection methods tend to discard informative but hard positive samples, leading to suboptimal training.
CARE Framework (Bottom Row):
The two-stage CARE framework addresses these issues as follows:
Stage 1: Calibration: Calibrates uncertainty to effectively isolate noise.
Stage 2: Refinement: Utilizes angular metrics and soft weighting to preserve hard positives.
Sample Legend:
Simple Sample: (indicated by Figure 1)
Noisy Sample: (indicated by Figure 3)
Hard Positive Sample: (indicated by Figure 5)
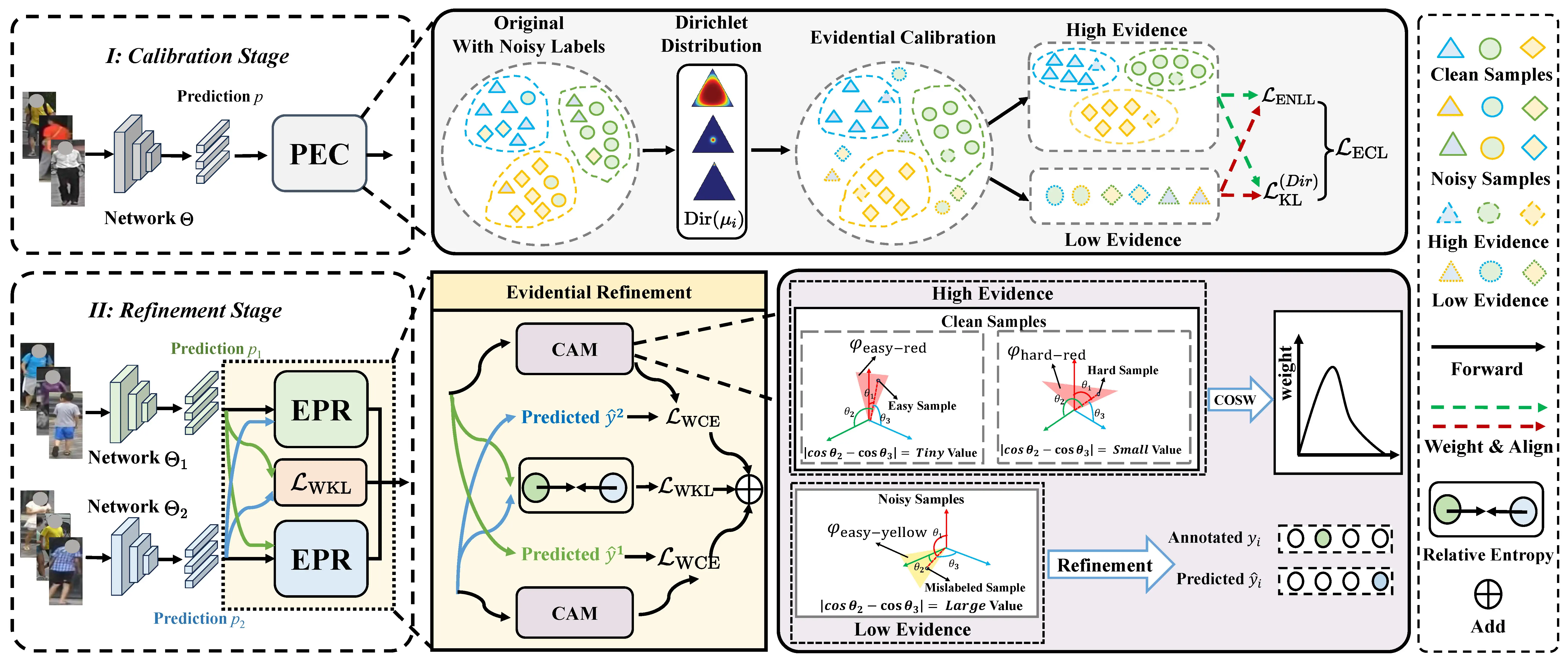
CARE framework
Detailed Two-Stage Paradigm:
Calibration Stage: PEC (Prototypical Evidential Calibration) integrates Dirichlet-informed prediction calibration to break softmax's translation invariance and mitigate over-confidence.
Refinement Stage: EPR (Evidential Prediction Refinement), powered by the CAM metric, surpasses small-loss methods in distinguishing clean but hard-to-learn samples from mislabeled ones; then COSW (Contribution-Oriented Sample Weighting) dynamically reallocates sample importance to prioritize clean instances over noisy instances.
Requirements
- Python 3.9
- pytorch 2.5.0
- tensorboardX
- scipy
- matplotlib
- easydict
- kornia
- ipykernel
- scikit-learn
Datasets
Market1501, Duke-MTMC and CUHK03
We follow Person_reID_baseline_pytorch to obtain the datasets.